

论文发布日期:2024-02-20
发布会议/期刊:ICMR2024(CCF-B)
ABSTRACT
- 探索了pre-trained vision-language models (VLMs)与最新的自适应(adaptation)方法结合在universal deepfake detection任务上的有效性
- 跟随之前的研究,作者仅仅使用单个数据集ProGAN来使CLIP适应deepfake detection任务。然而,之前的研究仅依赖于CLIP的视觉部分,作者则是在本文中结合了文本部分并分析了必要性
- 作者采用的轻量级的基于Prompt Tuning的自适应策略利用不到三分之一数据达到了SOTA效果
INTRODUCTION
- 目标
如何提高deepfake detection模型的泛化能力,如何有效迁移大模型到此任务上
动机
目前的deepfake detection模型在不同数据分布上的泛化能力有限。因为deepfake detection通常被视为有监督学习任务,因此如果模型专门针对特定类型的虚假图像进行训练时,在面对新类型的虚假图像时,该模型的性能会显著下降
Ojha提出要使用在初始训练阶段对不同范围的图像进行训练过的模型克服泛化困境,比如使用大型视觉语言模型CLIP。然而过去工作仅利用了CLIP的视觉模块进行linear probing,而没有充分利用CLIP强大的语言模块
在VLM领域(特别时CLIP)应用的基于Prompt的微调策略尚未在deepfake detection任务上得到探索,因此作者想要探究在VLM用于detection任务的众多选择中最有效的迁移学习策略

方法
利用CLIP提高泛化能力,并且尝试利用它强大的语言模块
利用不同策略训练CLIP,并就其鲁棒性进行实证分析,采用了四种方法:
Fine-tuning
Linear Probing
Prompt Tuning
training an Adapter Network
贡献
探究4种不同的迁移学习策略以提升CLIP在deepfake detection任务中的适应性和鲁棒性
证明Prompt Tuning策略明显优于其他技术
进行few-shot实验,证明模型仅仅接触32个LSUN类的样本,也能有强大的性能,证明了选择的轻量级的迁移学习的策略的有效性
利用JPEG压缩和高斯模糊等后处理操作对实验策略做鲁棒性分析
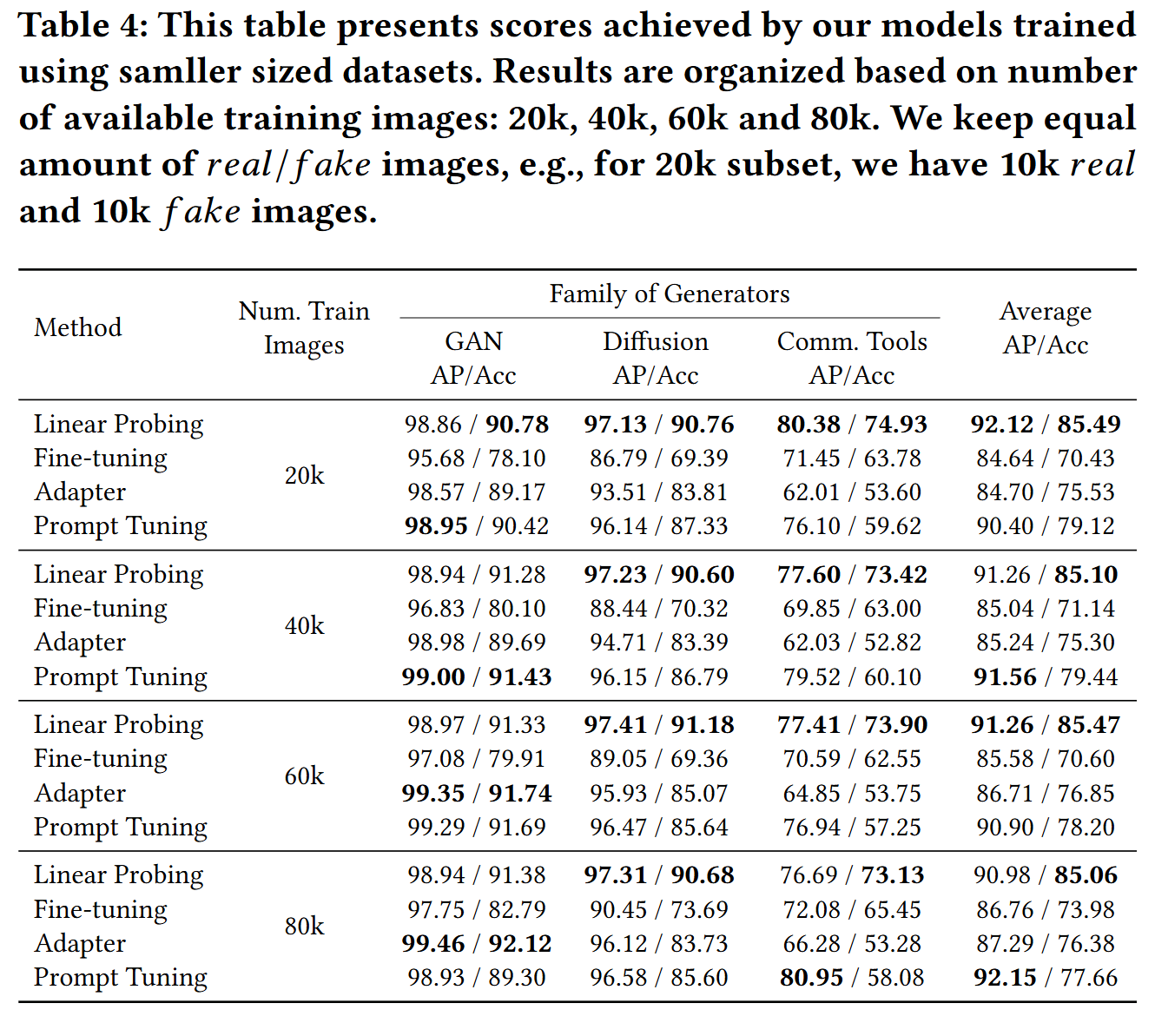
分析数据集大小的影响,证明使用较少数据,基于CLIP的检测器也很有效
Pre-trained Vision-Language Models

CLIP论文arxiv:http://arxiv.org/abs/2103.00020
Transfer Learning
即使CLIP有很强的zero-shot能力,但它依然需要对特定下游任务进行调整,不然有可能像在MNIST数据集上一样仅仅有55%的正确率
Context Optimization(CoOp)是一种微调策略,适应视觉语言模型的下游图像分类任务。CoOp将可学习的向量注入到文本提示上下文中(无论中前、中还是后),通过冻结CLIP的视觉和文本编码器,并在微调期间最小化分类损失来优化
CLIP-Adapter,a bottleneck layer,被设计来在微调期间学习新的特征。它利用了残差式的特征聚合方法,将最初CLIP的特征和新特征无缝集成,同时保持CLIP本身冻结
Fake Image Generation and Detection
Deepfake模型
- Goodfellow引入了Generative Adversarial Networks (GANs),a neural network architecture
for unconditional fake image generation。开创性的工作致力于改进GANs的训练过程、改进生成图像的质量和多样性和conditional image synthesis - 随着Diffusion的引入,文生图模型吸引了大家的注意,包括Stable Diffusion,SDXL,DALL-E,Imagen等。它们被证明了能够生成高质量图像,并且相比GANs有跨越不同类别和场景生成的能力
Deepfake detection模型
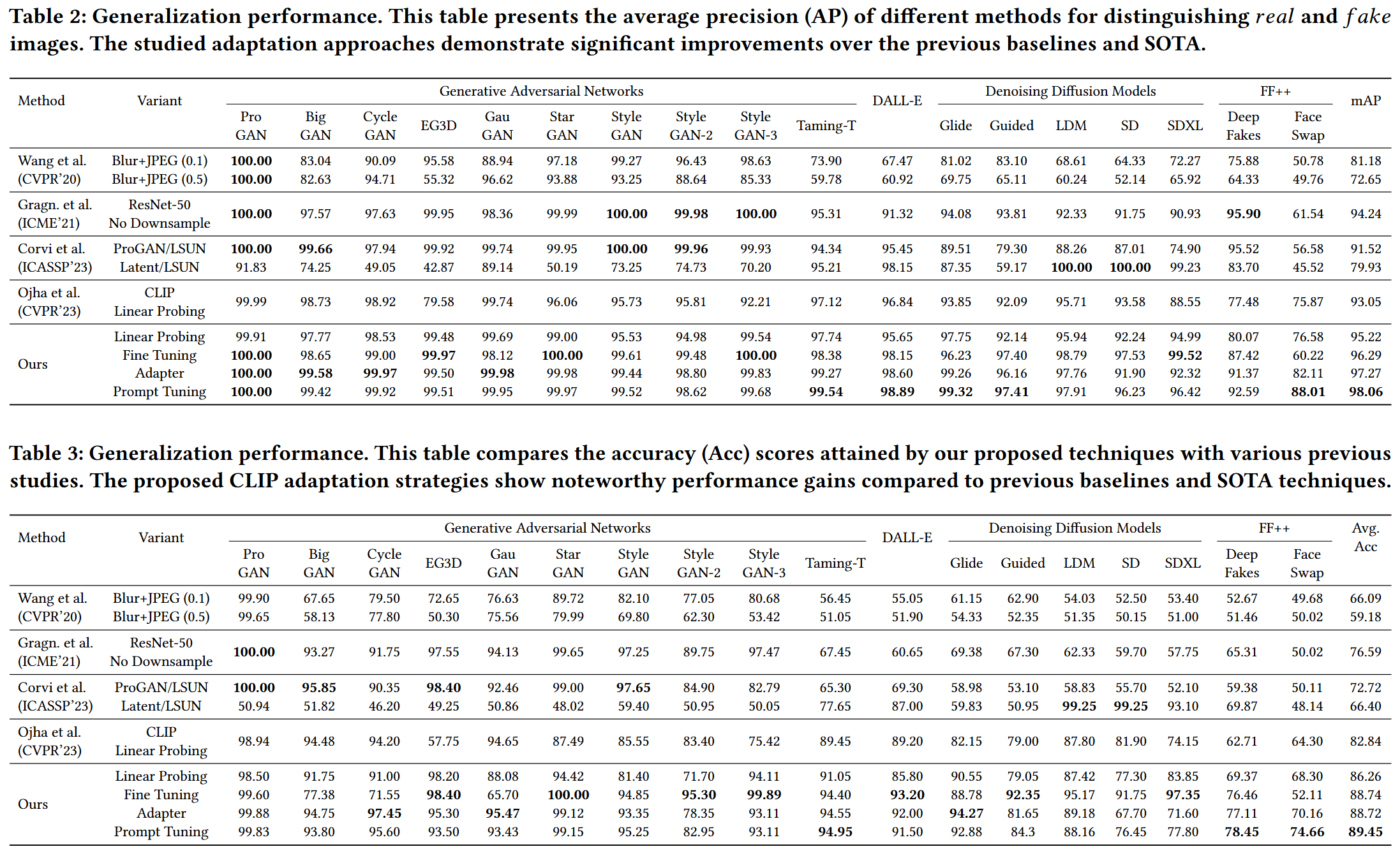
- Wang et al. 在单个GAN生成的数据集ProGAN上训练ResNet-50,并通过JPEG压缩和模糊等方法增强数据,显著提高了鲁棒性,能够在不同GAN模型生成的图像上表现良好
- 在Wang的基础上,Gragnaniello et al. 修改了ResNet-50,他们避免在初始层中进行下采样,以保留高频的GAN相关fingerprints,并利用了更强烈的增强方法
- Corvi et al.发现相同修改的ResNet-50在GAN上表现出色,但在Diffusion模型上表现不佳。然而在LDMs图像上训练的模型则恰好相反
- Ojha et al.指出了在单一假图像中训练的局限性,并利用冻结的CLIP图像编码器在特征层去训练线性分类头,只需在GAN上训练即可达到在两类模型都SOTA的效果,提高了泛化性
METHODOLOGY

四种方法
- Linear Probing:
冻结CLIP视觉编码器,丢弃文本编码器,训练单个线性分类头
- Full Fine-tuning:
相比原文中概述的微调方法,这里的文本没有使用模板而仅仅用了两个单词
- Training an Adapter Network:
CLIP-Adapter引入了一个额外的轻量级瓶颈层(bottleneck layer),在训练过程中只优化这个额外层,而CLIP模型的其余部分保持冻结状态。为了保持对未见过数据分布的鲁棒性,CLIP-Adapter通过ResNet风格的残差连接将原始的视觉或语言嵌入与微调后的嵌入集成在一起。CLIP-Adapter可以应用于文本或者视觉分支,本文只应用于视觉分支
- Prompt Tuning(leveraging CoOp):
CoOp附加可学习的向量在上下文单词中,向量可以用随机值或者预训练的词嵌入来初始化,训练中只优化学习向量
EXPERIMENTS
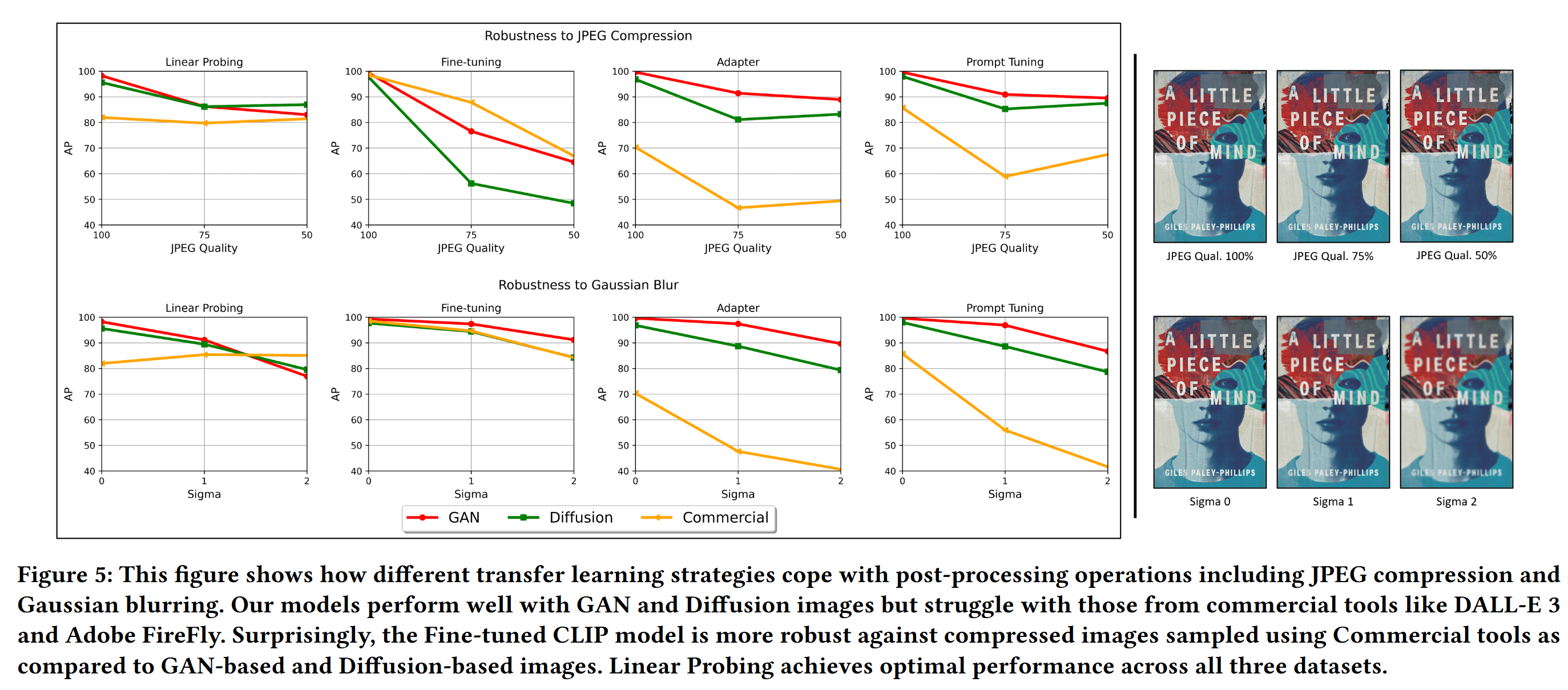
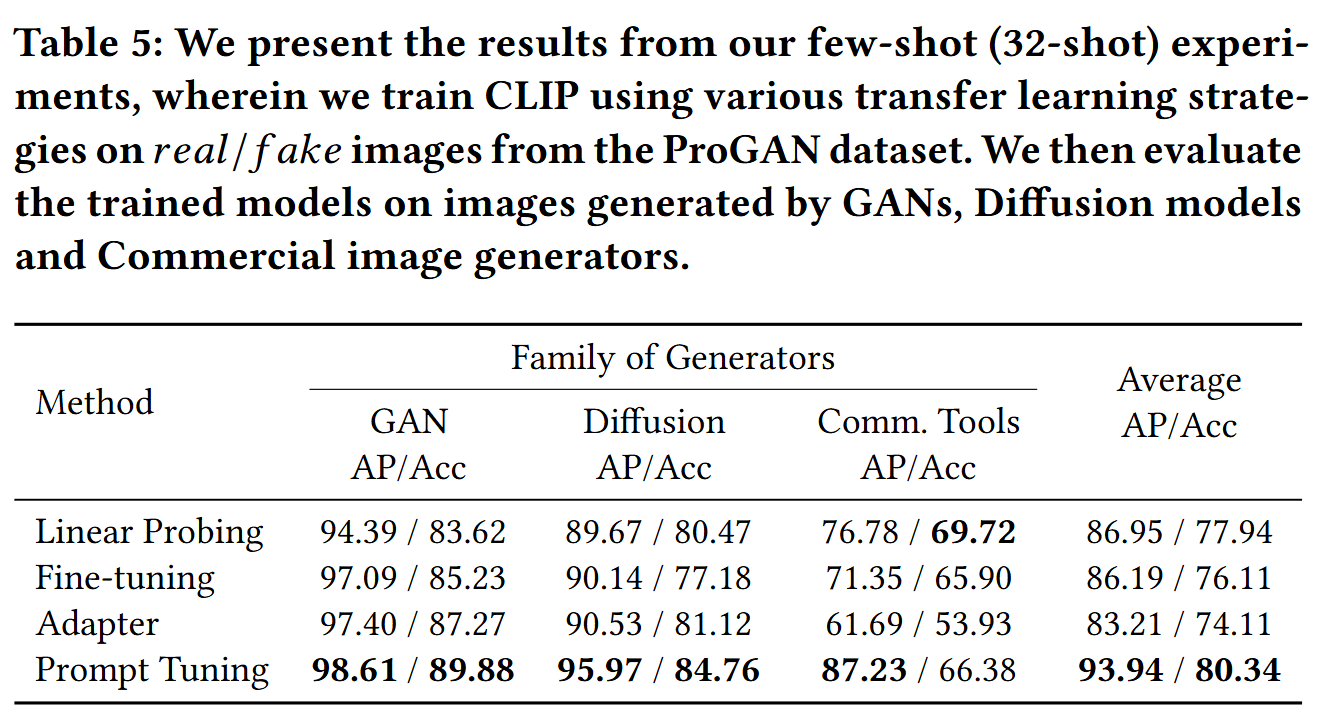
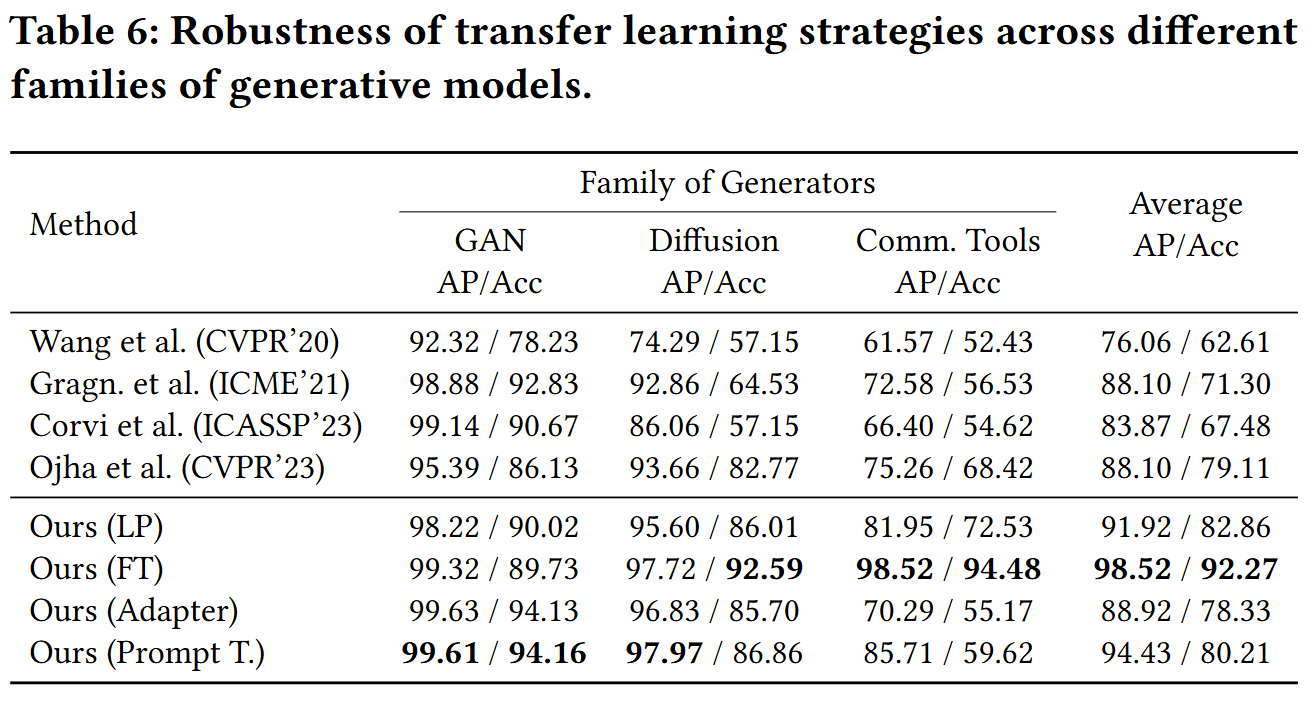
CONCLUSION
- 检验了CLIP在不同数据分布下deepfake detection的稳健性
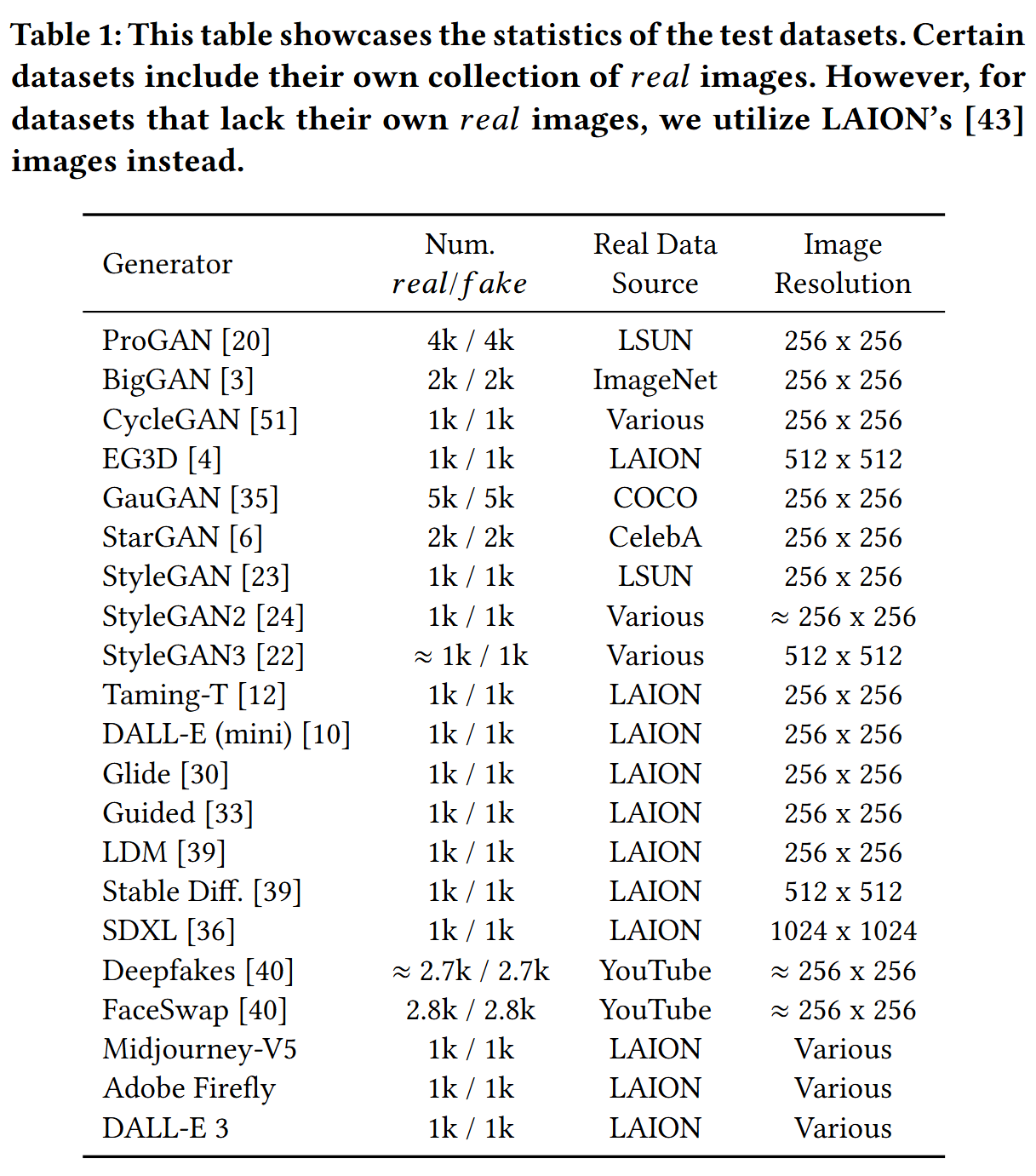
- 使用了来自ProGAN的200k张图片训练以实验4种不同的迁移策略,并且在有21个不同的图像生成模型的综合测试集中进行了评估
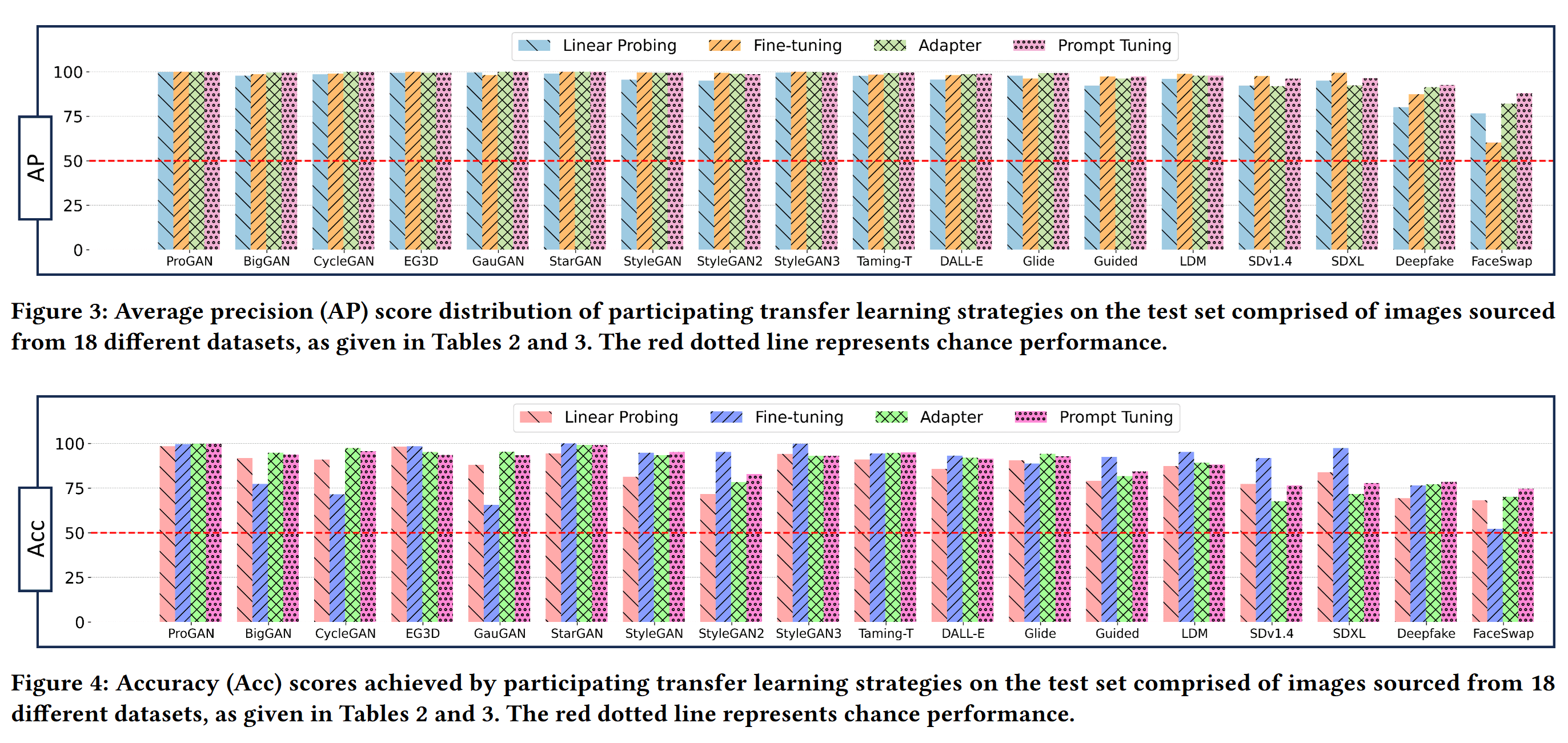
- 实验表明将CLIP的视觉和文本组件结合的迁移学习策略超越其他如Linear Probing等仅仅利用视觉模块的方法
- 强调了Prompt Tuning相对于当前baselines和SOTA方法的优越性,训练参数少的同时效果较好
- 对图像进行了JPEG compression和Gaussian blurring这两种后处理以检验稳健性