

论文发布时间:2024-03-30
发布会议/期刊:ECCV
Abstract
- 探究问题:能否将所有时空tokens输入LLM,利用LLM来直接进行视频序列建模任务。
- 提出ST-LLM,一种有效的video-LLM baseline,有效提升了在LLM内建模时空序列能力。
- 开发了一种具有定制训练目标的动态掩码策略,以解决LLMs内未压缩视频tokens带来的开销和稳定性问题。
- 对于特别长的视频,设计了全局本地输入模块平衡效率和效果。
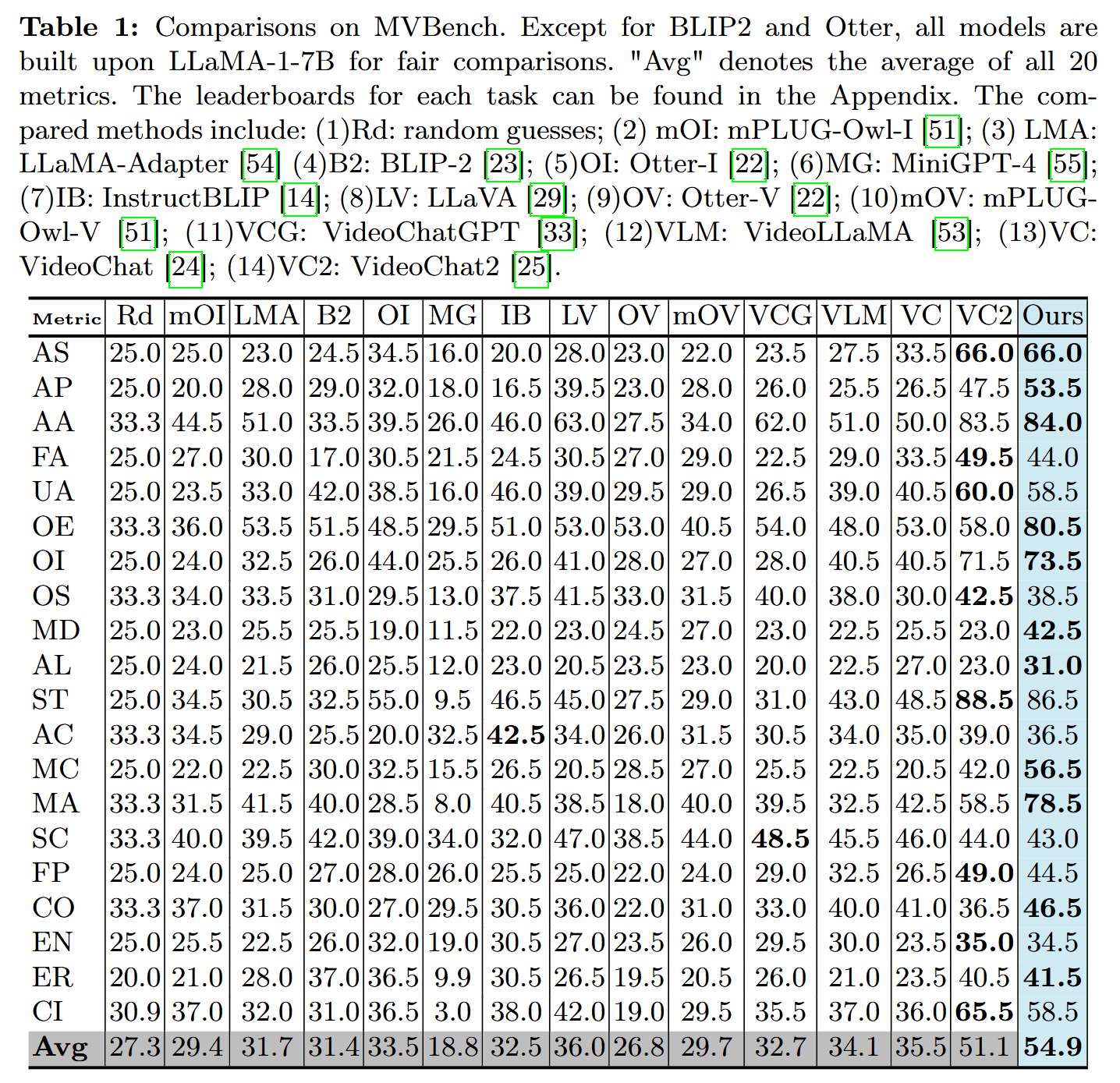
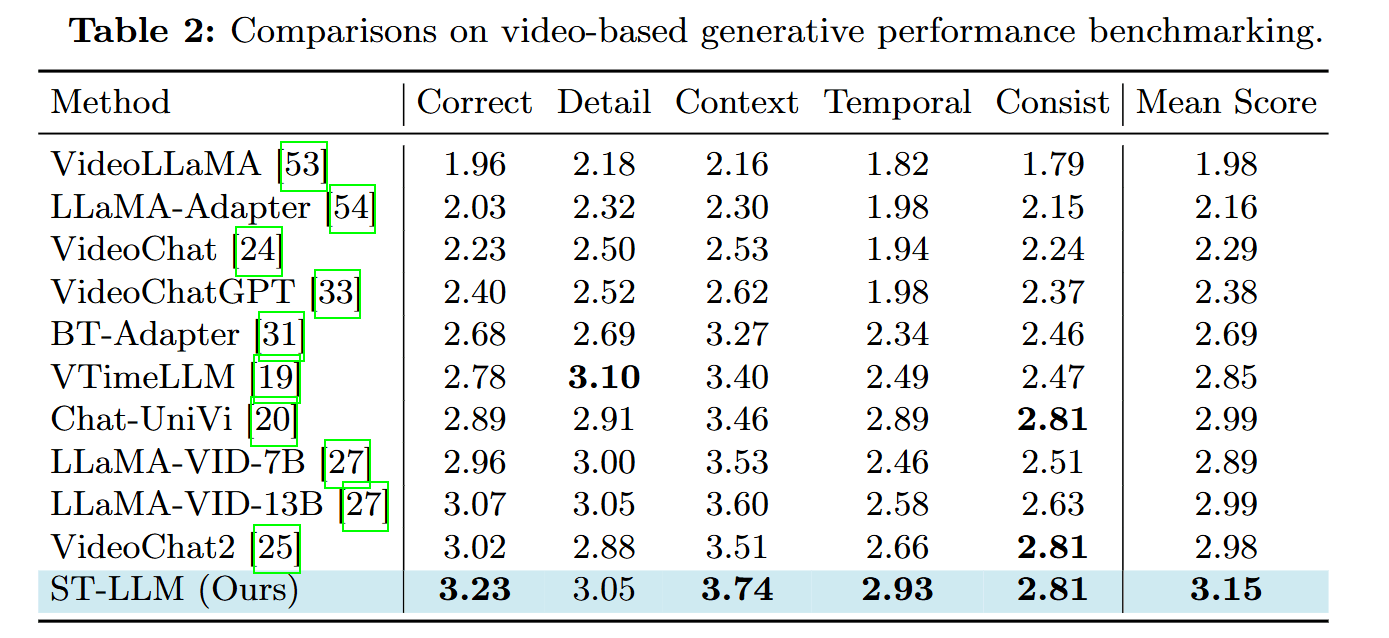
- 总结,利用LLM进行时空序列建模,保证稳定和效果的同时,在VideoChatGPT-Bench和MYBench达到了SOTA。
Introduction
目标
如何直接委托LLMs进行时空建模任务,而不用引入额外的结构。
动机
许多LLMs已经拥有了生成视频内容通用摘要的能力,但是LLMs在严重依赖理解时间动态的内容时还是表现出了不足。现在最好的LLM展示了理解静态上下文操作的强大理解能力,但是理解涉及运动的场景仍然受到限制,甚至无法辨别物体运动最基本的方向。
早期的VLM倾向于在时间维度使用平均池化,但这不足以处理动态时间序列。因此最近有模型经常集成用于时间采样和建模的附加结构,虽然提高了效果但需要增加存储空间并且需要耗费大量gpu时间从头开始训练,并涉及两个甚至三个阶段预训练来对齐新模块。
没人尝试过直接将时间建模任务委托给LLM,因为引入了额外挑战:
- 所有视觉tokens显著增加LLMs处理上下文的长度,使其难以承受。
- LLM难以处理不同长度视频,当测试和训练帧数存在差异时,容易导致幻觉。
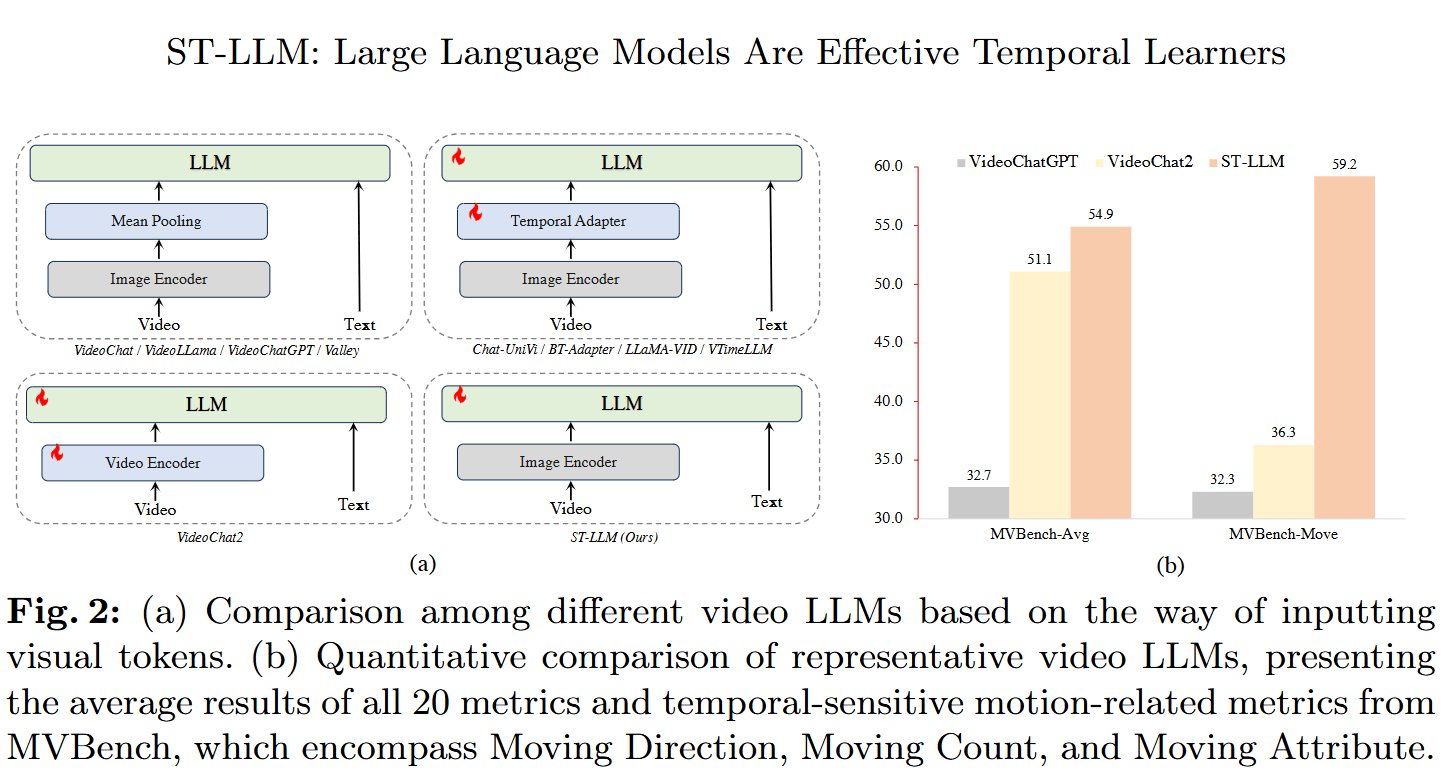
方案
直接利用原始的时空tokens在LLMs内部进行鲁棒的时间序列建模。
引入了dynamic video token masking strategy,并使用masking video modeling进行训练,在减少输入到LLM的序列长度的同时显著提高了推理过程对不同长度视频的鲁棒性。
对长视频设计了独特的lobal-local input mechanism,采用大量帧的平均池化来生成较小帧子集的residual input。这种非对称涉及可以处理来自大量视频帧的输入同时保留LLM内部建模操作。
贡献
- 提出ST-LLM,第一个探索LLM内部时空建模的开源LLM模型。
- 提出了dynamic video token masking strategy和masking video modeling方法,此外还引入了用于处理长视频的lobal-local input mechanism。保证了LLM内部时空token处理的效率和稳健性。
- 在各种视频对话benchmarks上,ST-LLM始终优于现有视频LLMs,特别是需要强大的时间理解能力的任务。
LLMs and Image LLMs
Inspired by InstructGPT and the widely recognized commercial model ChatGPT, the academic community has seen a proliferation of open-source LLMs, such as LLaMA, Alpaca, Vicuna, and LLaMA 2, which have become foundational components for a myriad of research endeavors
The success of LLMs has spurred increasing interest in the development of Multimodal Large Language Models (MLLMs). Notable breakthroughs include works such as Flamingo, BLIP2, and PaLM-E, which have successfully bridged the gap between vision models and LLMs
在LLM时代前,视频建模多是基于图片模型构建,因此可以认为预训练图片对话模型同样可以为LLMs提供训练成本和性能上的优势
Video LLMs
- The emergence of MLLMs quickly extended into the domain of video as well. Early models like VideoChat, VideoChatGPT and Valley generate video instruction tuning data through GPT to enable video conversations.
常涉及使用平均池化聚合各个帧的编码结果,不足以进行有效建模
some subsequent models have initiated exploration into adaptations of image models to video-specific requirement
BT-Adapter proposed a lightweight adapter to extend the capabilities of image LLMs
Chat-UniVi introduces DPC-KNN to cluster dynamic visual tokens
VideoChat2 deviated from using CLIP and directly introduced a dedicated video encoder for video encoding
这些方法相比于平均池化提供了改进,但包含的附加模块通常需要进行大量训练。
例如VideoChat2,引进的视频编码器需要三阶段包含30M视觉文本数据的训练。
ST-LLM则采用更直接的方法,将视觉序列建模任务委托给LLM,减少训练需求,更加简单。
Joint Spatial-Temporal Modeling
Prior to the emergence of LLMs, joint spatial-temporal modeling had demonstrated effectiveness in both video-only and video-language pretraining
- More recently, inspired by DIT, the popular video generation model Sora has shown success in simultaneously processing video tokens and text using the transformer
Despite its potential, joint spatial-temporal-text modeling remains relatively uncommon in video
LLMs
- While VideoChat2 employed a joint-ST video encoder, it necessitated extensive pretraining
- InstructBLIP incorporated joint spatial-temporal sequences into LLM for zero-shot evaluation on video datasets.However, this approach led to significant hallucinations due to the absence of video instruction tuning
ST-LLM是第一个采用联合时空文本建模的开源视频LLM。此外ST-LLM做的一系列设计创新可以减轻将视频tokens纳入LLM的众多限制。
Methodology
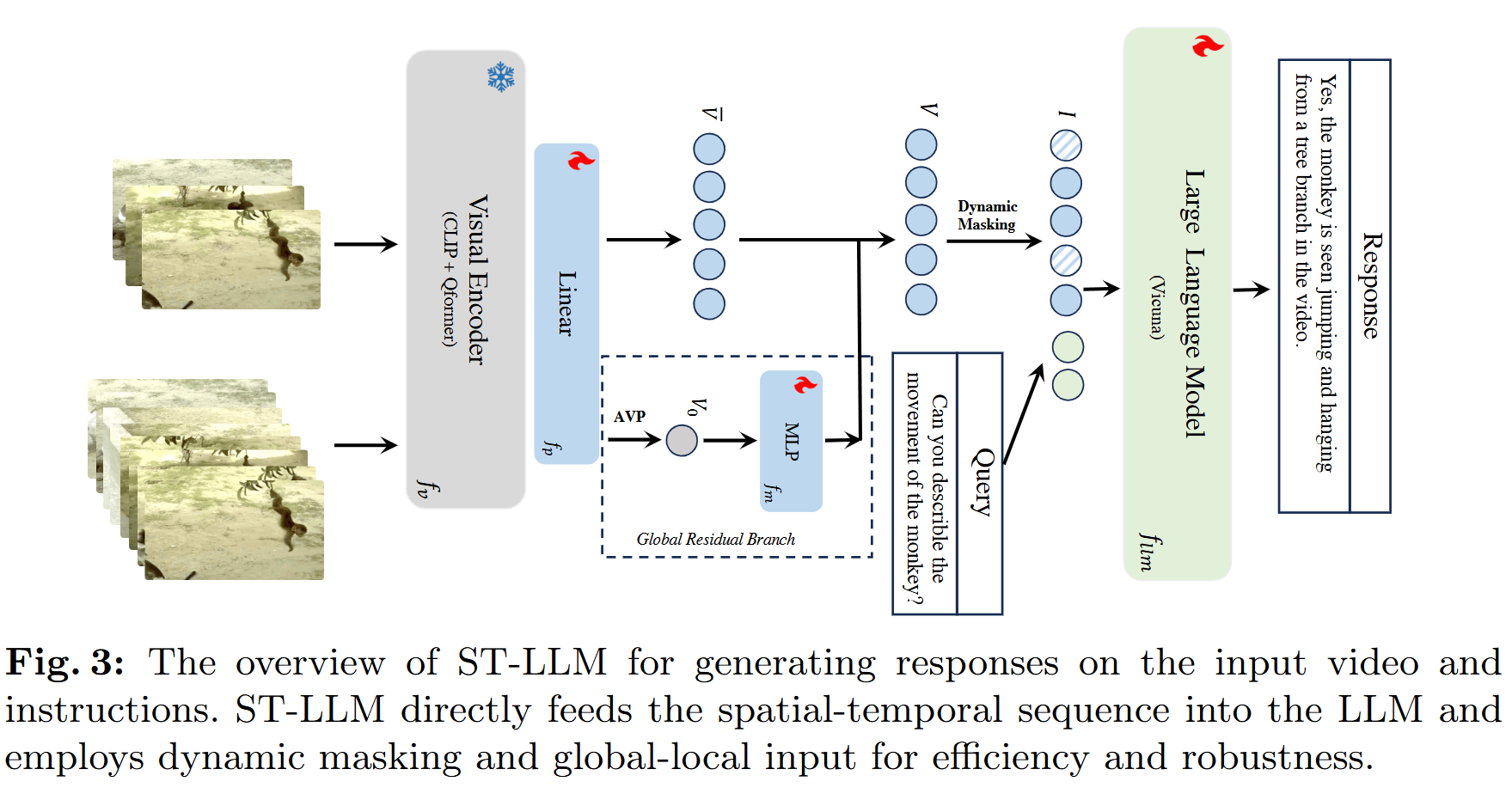
Video Tokens Inside LLM
文本编码器:CLIP
视觉编码器:BLIP-2(Q-Former)
给定一个有
其中
然后,我们将所有视觉标记连接起来,形成一个联合的时空序列
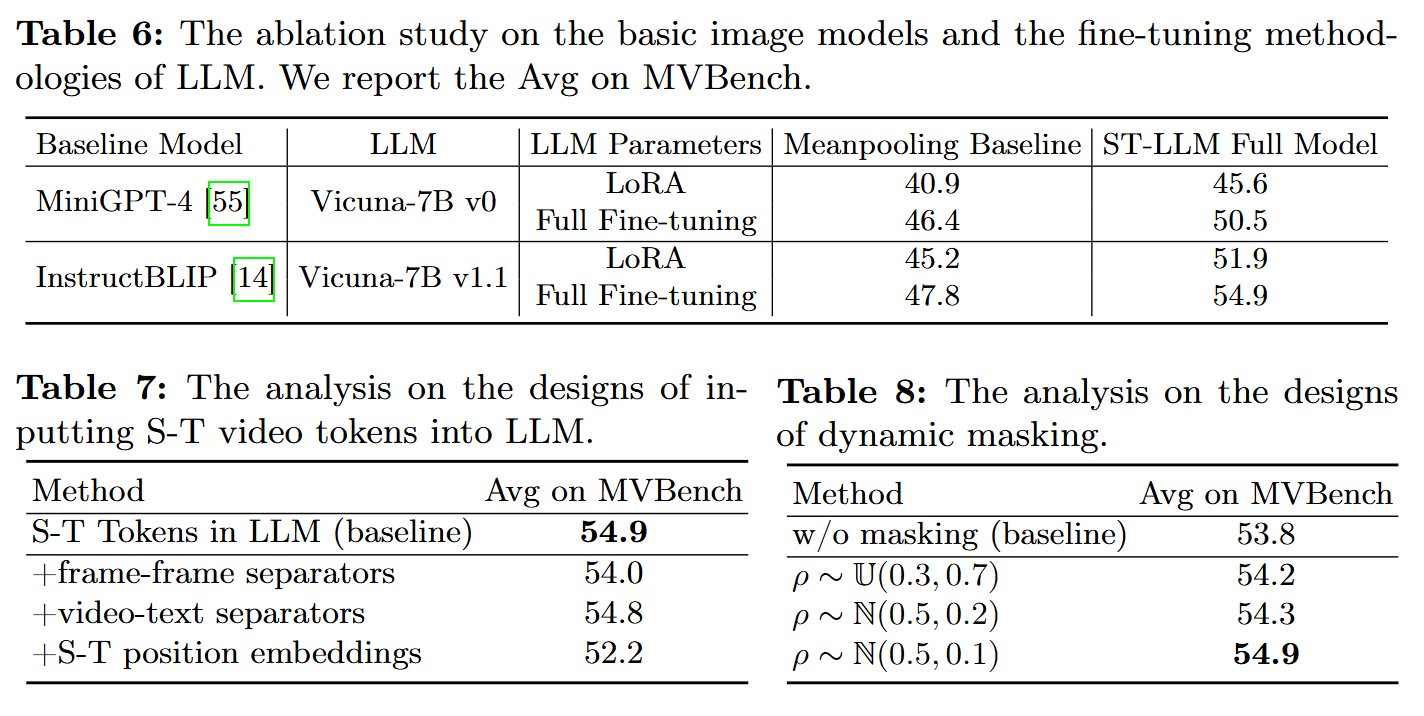
在将输入标记输入到 LLM 之前,存在几种替代策略。
- 添加分隔符标记在帧内标记或视觉-文本标记之间,以划分模态或帧之间的边界。
- 专门为视觉标记添加时空位置嵌入,以促进更好的时空关系理解。
但实验表明,简单性往往能产生最佳效果。添加许多分隔标记会引入额外的开销,而不会显著提高性能。此外,LLMs 带有旋转位置嵌入,它已经有效地区分了所有时空标记和文本标记的位置。
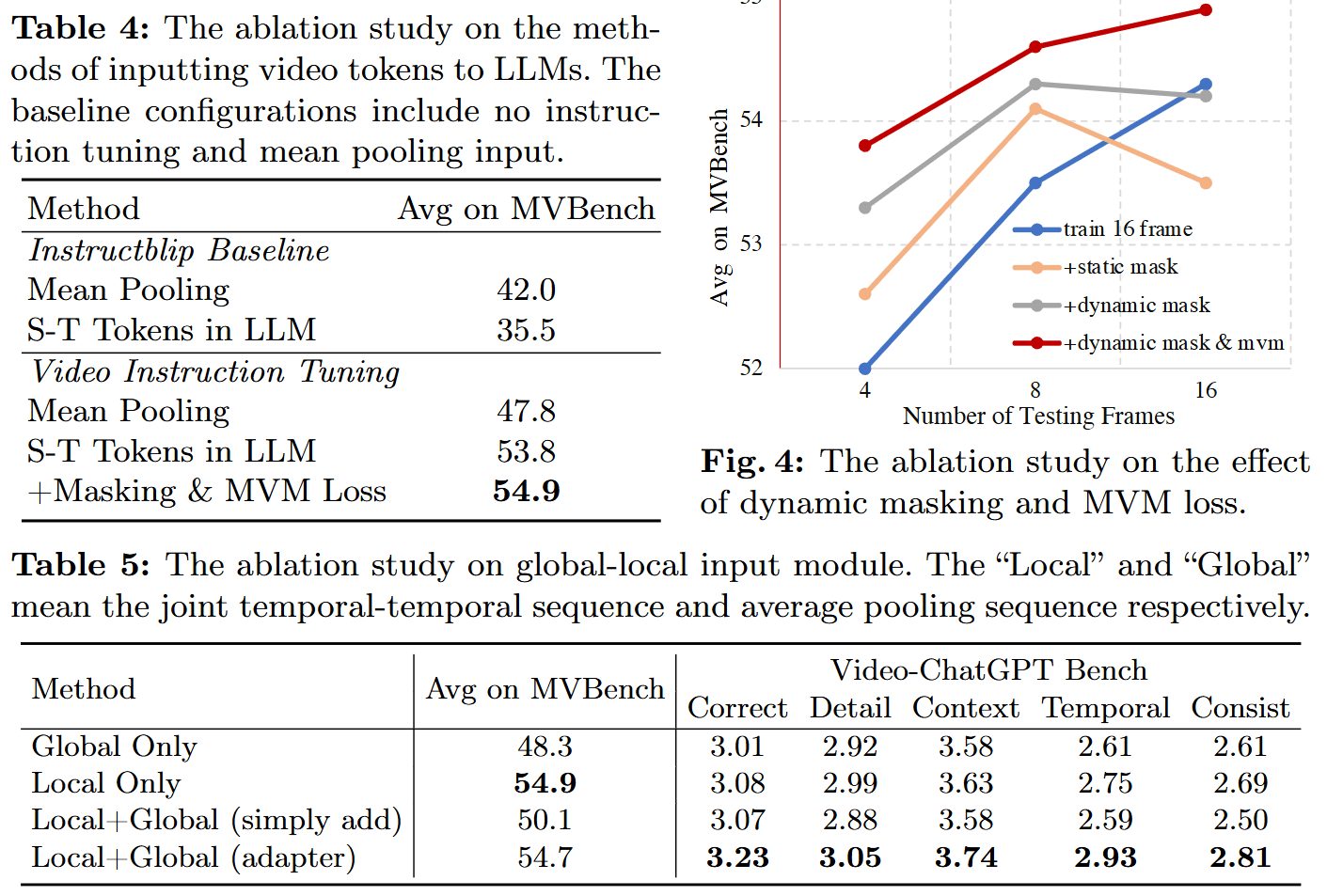
Training with Dynamic Masking
为了解决输入帧长度过长的问题,作者提出在训练过程中对视觉标记进行掩码。
保持
其中
此外,基于动态掩码,作者制定了掩码视频建模(MVM)训练目标,以鼓励LLM掌握时空依赖关系。具体来说,除了掩码序列
其中
通过整合这两个损失组件,我们可以鼓励LLM有效地响应视频内容派生的问题,同时提高其建模时空依赖关系的能力。
Global-Local Input
尽管压缩了输入帧,但是对于极长视频需要大量帧的情况仍然无法处理。
因此,作者又设计了一个额外的模块来解决这个问题。
具体来说,给定一个帧数较多的长视频,仍然从对每帧单独编码以获取
接下来,我们从总共
其中
通过这种全局-局部输入设计,LLM内低帧率时空序列可以逐渐整合来自高帧率分支的信息。该方法允许模型在有限的上下文中受益于LLM建模时空序列的能力,同时也考虑到长视频的全局信息。
Experiments
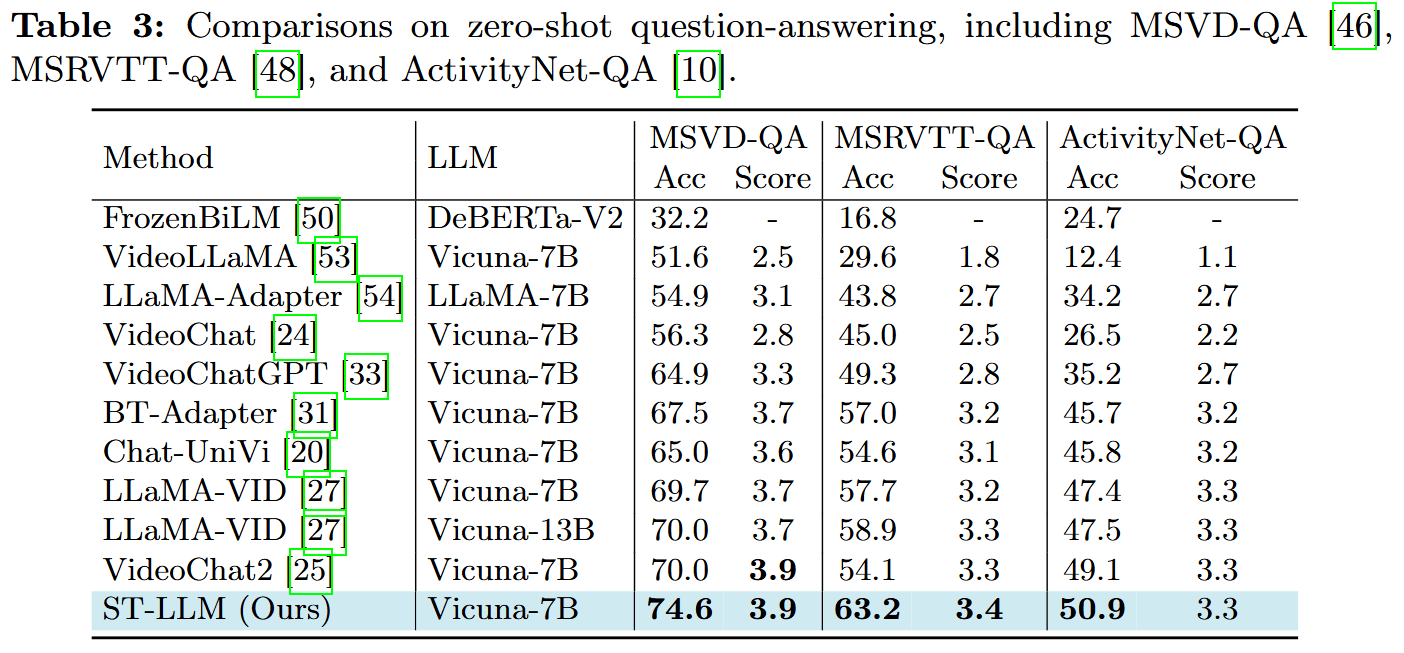
Conclusion
- 提出了ST-LLM,框架简单而强大,在很多benchmark实现SOTA。
- 直接利用LLM对视频标记进行建模以实现有效的视频理解,此外引入了动态屏蔽策略和全局局部输入模块来增强该框架的鲁棒性。