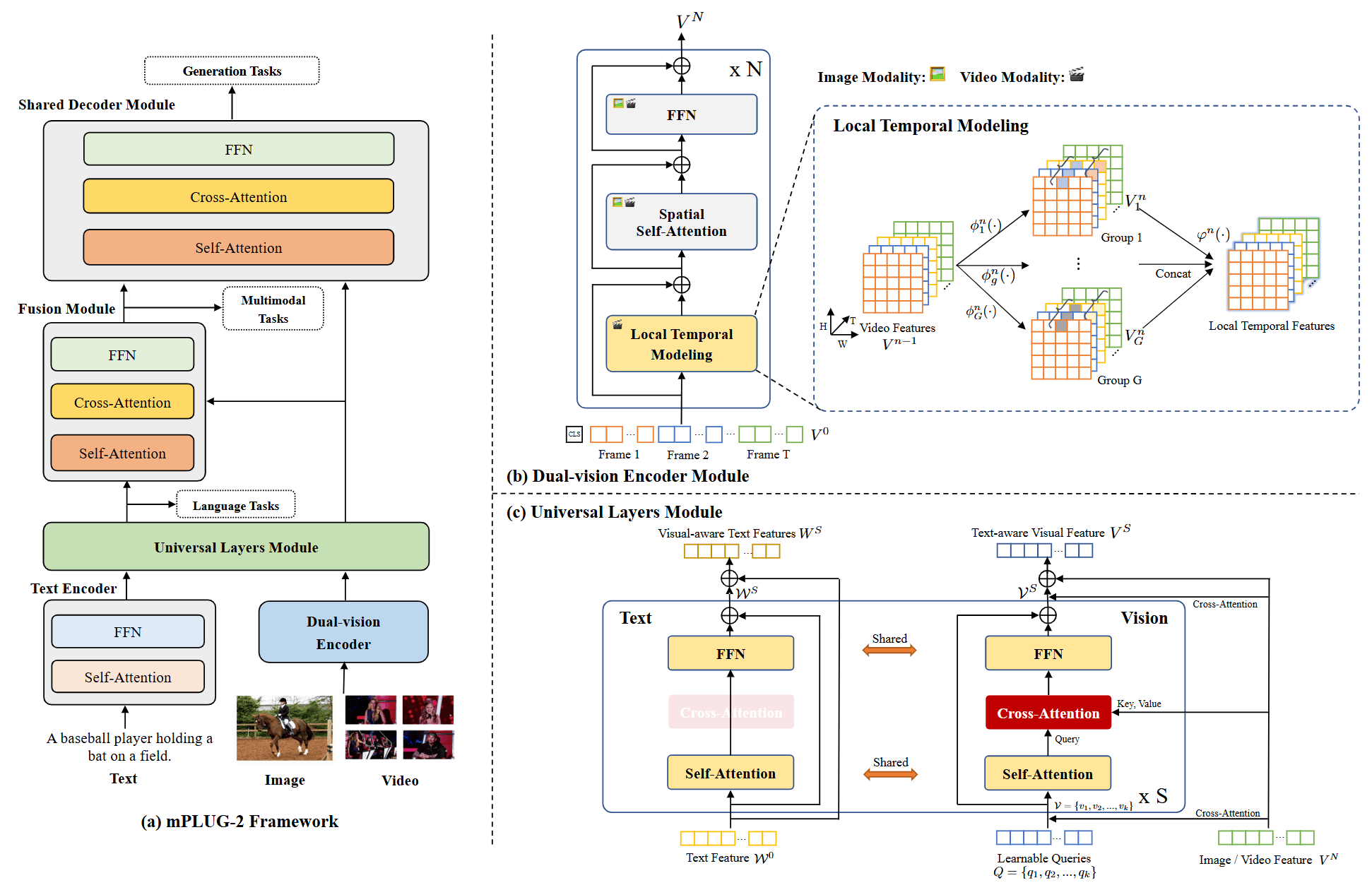
前言

之前这篇综述看完后只有文字,很多模型架构不懂,所以重新进行写一篇笔记,将典型的一些时空大模型架构进行整理。注意我只写了一些我关心的内容。
LARGE MODELS FOR TIME SERIES DATA
Large Language Models in Time Series
OFA(NeurIPS 2023)
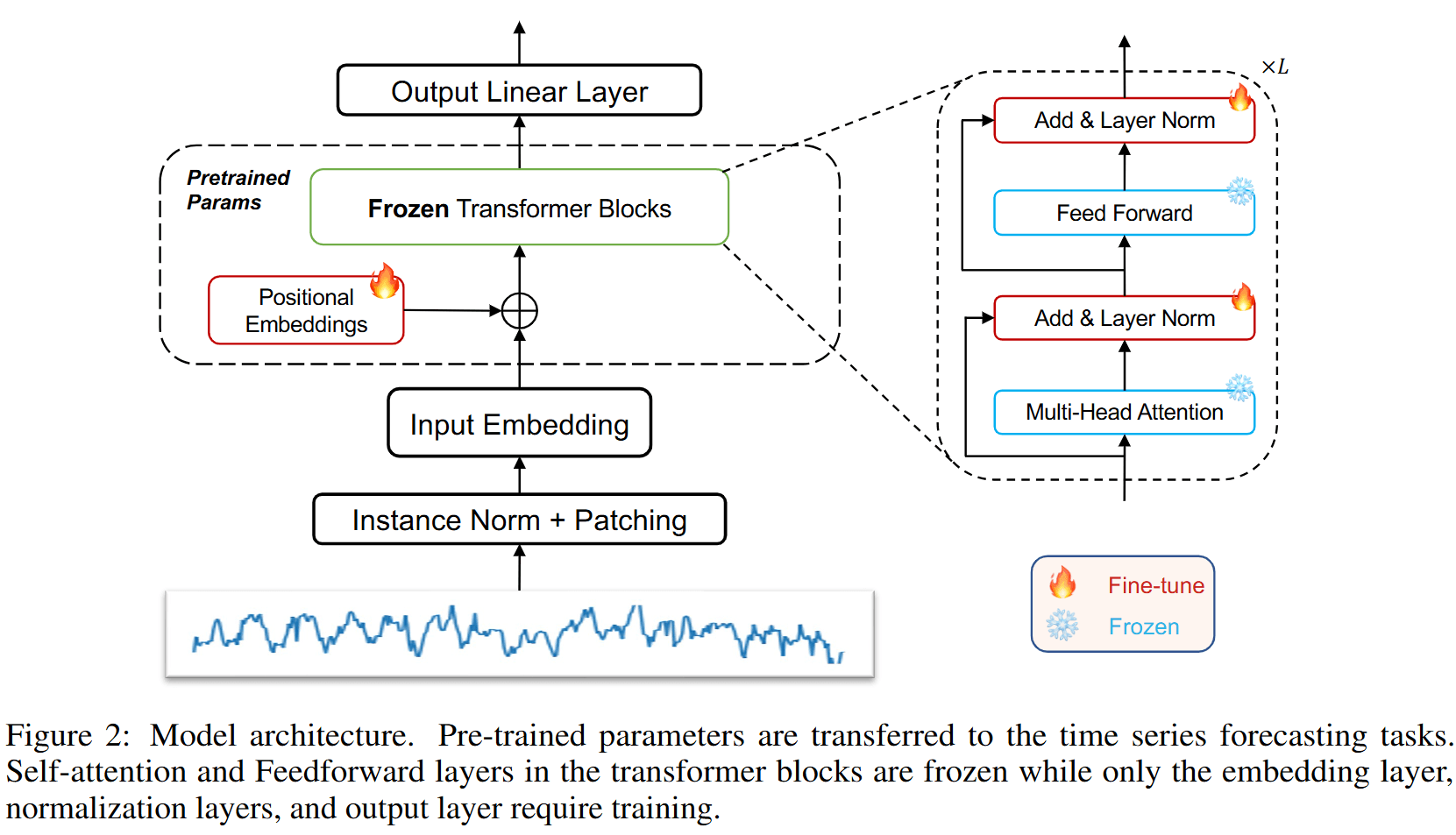
方法的核心思想是在不改变预训练模型中自注意力(Self-Attention)和前馈神经网络(Feedforward Neural Networks, FFN)层的情况下,利用这些预训练层在自然语言处理(NLP)或计算机视觉(CV)领域中学到的丰富知识,应用于时间序列分析任务。
具体流程如下:
- 选择预训练模型:
- 主要以GPT2为例,但也实验了其他预训练模型如BERT和BEiT,以验证跨模态知识迁移的通用性。
- 输入处理:
将原始的多元时间序列数据视为多个独立的单变量序列。
对每个序列进行逆实例归一化(Reverse Instance Norm),以标准化数据分布。
使用切片方法(Patching)将时间序列分割成若干个patch,每个patch包含连续的时间步,以形成patch-based token。
- 嵌入映射:
- 通过重新设计的输入嵌入层(线性探测层)将patch token映射到预训练模型的嵌入空间。
- 冻结与微调:
- 输入映射后的嵌入数据通过冻结的自注意力和FFN层进行处理。这些层保留了预训练模型在NLP或CV任务中学到的通用特征表示能力。
- 通过微调后的位置嵌入层和归一化层,调整模型以适应特定的时间序列分析任务。
- 输出层:
- 最终通过输出的线性层生成预测结果。
Time-LLM(ICLR 2024)
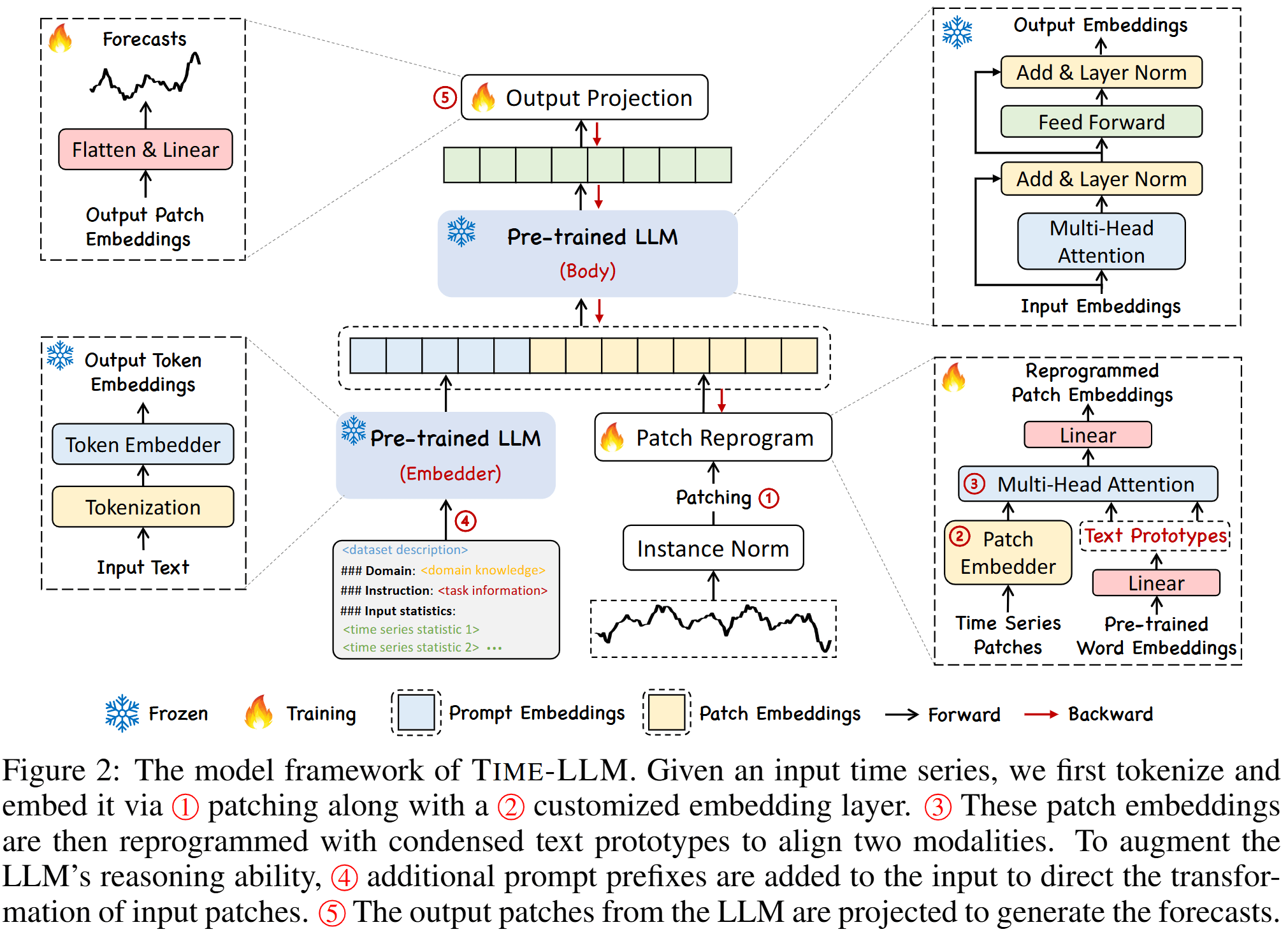
TIME-LLM方法旨在通过重编程(reprogramming)大型语言模型(LLMs)来实现通用的时间序列预测,而无需修改预训练的语言模型主体。
总体架构如图所示,TIME-LLM的主要流程包括以下步骤:
Input Embedding
标准化:首先,对每个输入通道的时间序列数据
进行可逆实例标准化(Reversible Instance Normalization, RevIN),使其均值为0,标准差为1,以减轻时间序列分布的变化带来的影响。 Patching:将标准化后的时间序列
划分为若干个连续或不重叠的补丁,每个补丁长度为 。总补丁数为 ,其中 为滑动步幅。划分补丁的动机包括: - 更好地保留局部语义信息,将局部信息聚合到每个补丁中。
- 作为标记化(tokenization),形成紧凑的输入序列,减少计算负担。
嵌入:使用一个简单的线性层将每个补丁
嵌入到维度为 的向量空间,得到嵌入向量 。
Patch Reprogramming
目标:将时间序列的嵌入向量
转换为适合语言模型处理的文本原型表示,以对齐时间序列数据和自然语言的模态。 文本原型(Text Prototypes):原始词嵌入为
,作者引入一组学习得到的文本原型 ,其中 ,用于连接语言模型的词汇表与时间序列数据。文本原型通过多头交叉注意力层(Multi-Head Cross-Attention)进行优化,使其能够有效地表示时间序列的局部信息。 Reprogramming过程:
对每个注意力头
,定义查询矩阵 ,键矩阵 值矩阵 。 通过注意力机制计算重编程后的补丁表示:
- 将所有头的输出
聚合,线性映射到与语言模型隐藏层维度一致的向量 。
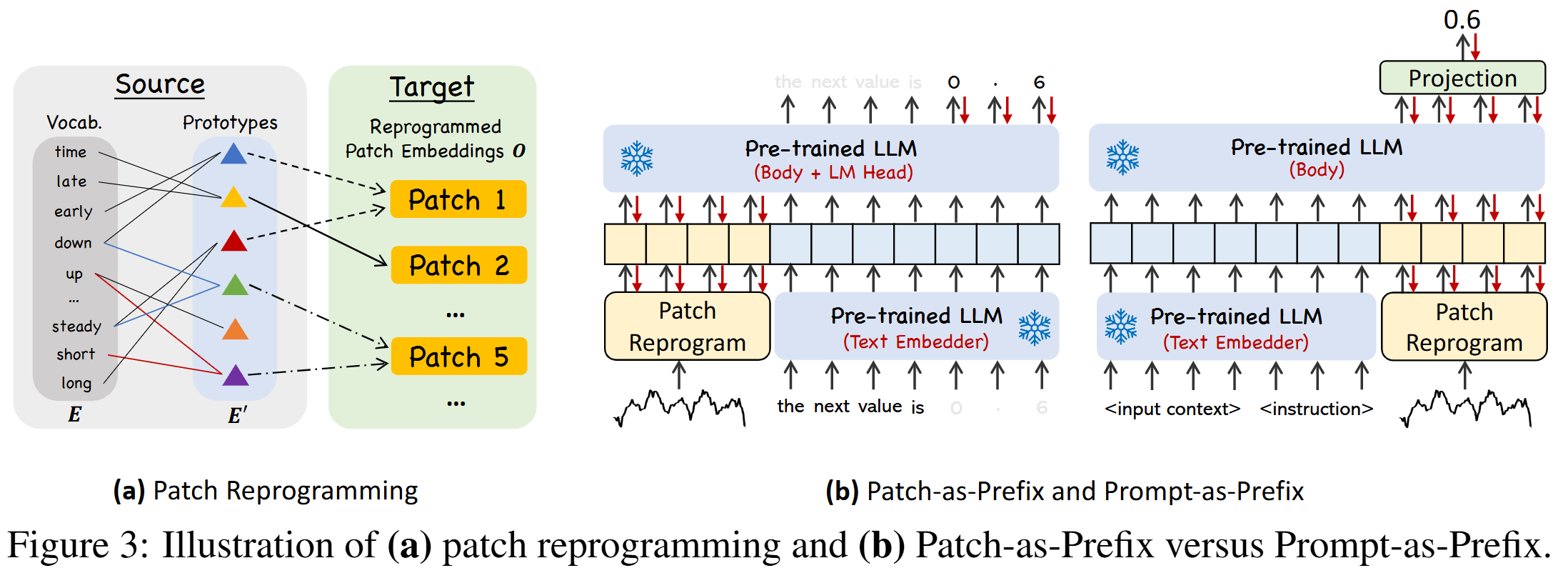
Prompt-as-Prefix(PaP)
动机:直接将时间序列转换为自然语言存在挑战,尤其是在处理高精度数字和不同语言模型的标记化方式上。因此,引入了一种Prompt-as-Prefix的方法,通过在输入上下文前添加提示(prompts),以指导语言模型对重编程后的补丁进行转换和推理。
组成部分:
- 数据集上下文(Dataset Context):提供输入时间序列的背景信息,例如领域特性和数据描述。
- 任务指令(Task Instruction):明确指导语言模型进行特定任务的指令,如预测未来步数。
- 输入统计信息(Input Statistics):包括趋势、滞后等统计特征,帮助模型识别和理解时间序列模式。
实现方式:将上述三个组成部分整合为自然语言格式的提示,作为输入嵌入之前的前缀,提供额外的上下文和指引,从而增强模型对时间序列数据的理解和推理能力。

Output Projection
- 过程:
- 将包含prompt和重构后的patch输入通过冻结的LLM前向传播,获得输出表示
。 - 丢弃前缀部分,仅保留与时间序列补丁对应的输出表示。
- 对输出表示进行展平(flatten)和线性投影,生成最终的预测结果
。
- 将包含prompt和重构后的patch输入通过冻结的LLM前向传播,获得输出表示
- 训练策略:在整个流程中,仅更新输入转换和输出投影的参数,而保持语言模型主体(backbone LLM)冻结。这种方式避免了大规模的模型微调,提升了训练效率,并减少了资源消耗。
- 过程:
Pre-Trained Foundation Models in Time Series
STEP(KDD 2022)
本文提出了一种新的框架,将空间-时间图神经网络(STGNNs)与可扩展的时间序列预训练模型相结合,称为 STEP。该框架主要包括两个阶段:预训练阶段和预测阶段。
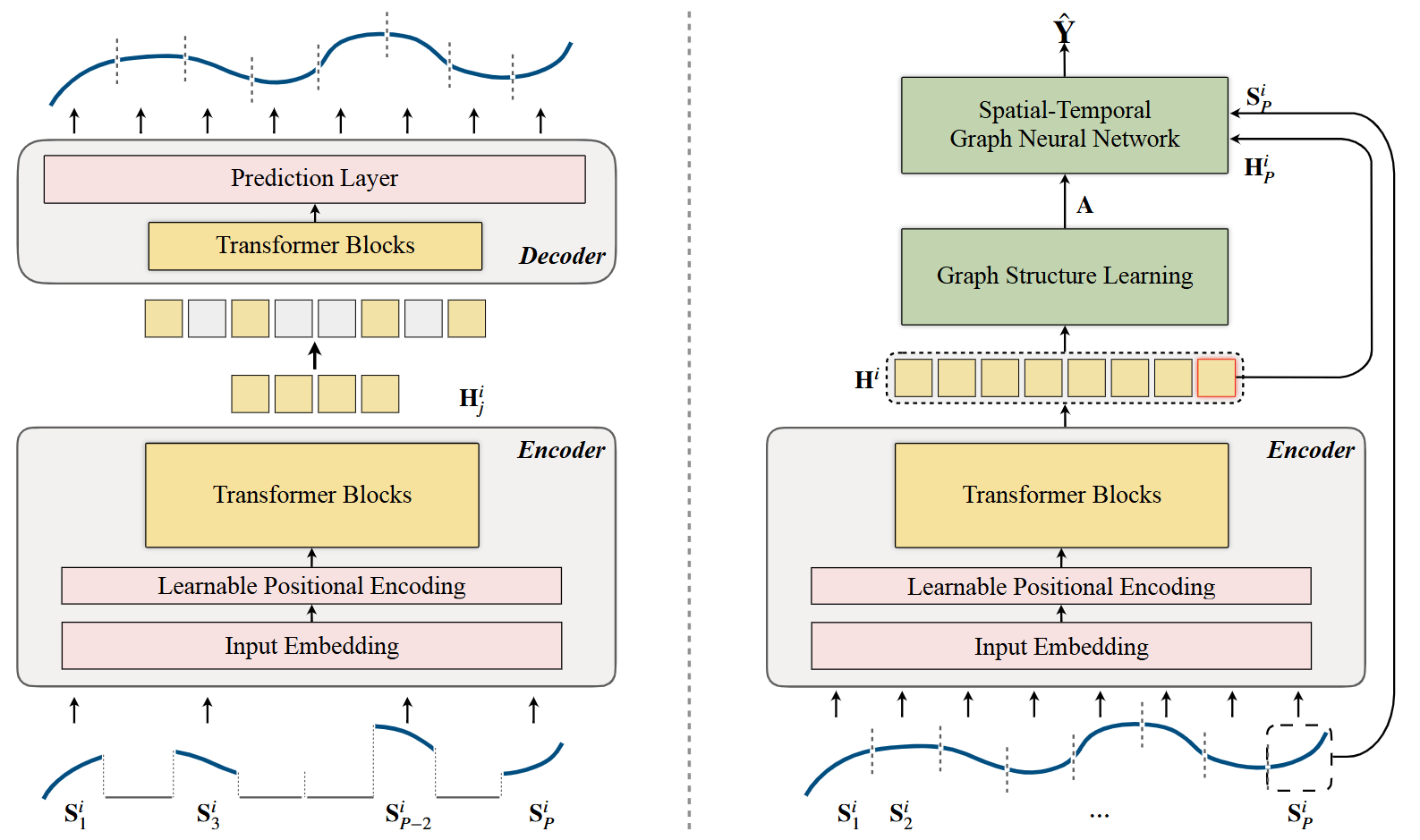
预训练阶段
在预训练阶段,作者设计了一个基于 Transformer 块的时间序列自编码模型,称为 TSFormer(Time Series based on Transformer blocks)。该模型通过掩码自编码策略进行训练,旨在高效地从超长时间序列中学习时间模式,并生成包含丰富上下文信息的段级表示。
输入处理
给定时间序列
,其中 表示时间步数, 是通道数。我们将长时序序列划分为 个不重叠的patches,每个patch的长度为 : 其中
。 掩码学习
我们随机掩盖一部分patches,掩码比例为
(通常设置为 75%),以创造一个具有挑战性的自监督任务。被掩盖的补丁使用一个共享的可学习掩码标记(mask token)替代。 编码器
编码器由一系列 Transformer 块组成,仅对未被掩盖的补丁进行操作。首先,将未掩盖的补丁通过输入嵌入层映射到隐藏空间:
其中
, 是可学习参数, 是隐藏维度, 为模型输入向量。 接下来,添加可学习的位置编码(positional encoding)以保留时序信息。注意,位置编码作用于所有ptaches,尽管掩码标记在编码器中未被使用。
Transformer 编码器生成未掩盖patches的隐藏表示
。 解码器
解码器也是一系列 Transformer 块,作用于完整的patch集合(包括掩码标记),将隐藏表示重建回原始的数值信号。解码器仅在预训练阶段用于执行序列重建任务。最终,通过多层感知机(MLP)预测每个补丁的重建序列:
其中
。 损失函数
我们使用平均绝对误差(MAE)作为损失函数,仅在被掩盖的补丁上计算:
其中
为被掩盖的补丁集合。
预测阶段
在预测阶段,我们利用预训练的 TSFormer 编码器为每个时间序列产生段级表示,这些表示提供了丰富的上下文信息,可用于增强下游的 STGNN,进行图结构学习预测。
图结构学习
为了学习时间序列之间的依赖关系(即时间序列之间的图结构),作者设计了一个基于表示的图结构学习模块。
首先,获取时间序列
的表示: 其中
表示连接操作, 。 接下来,计算
和 之间的相似度,以构建初始的 近邻图 。 为了参数化边缘的存在概率,我们定义:
其中
为未归一化的概率, 为时间序列 的全局特征,通过卷积网络获取。 使用 Gumbel-Softmax 重参数化技巧,我们从
中采样得到邻接矩阵 : 其中
是从 Gumbel(0,1) 分布中采样的噪声向量, 是温度参数。 图结构正则化损失定义为:
其中
。 下游 STGNN 模型
下游的 STGNN 模型(例如 Graph WaveNet)以最后一个patch
和学习到的依赖图 作为输入。我们融合 TSFormer 生成的表示和 STGNN 的隐藏表示,具体为: 其中
是语义投影函数,将 TSFormer 的表示映射到 STGNN (即 )的语义空间,通常通过 MLP 实现。 表示由下游 STGNN 模型生成的隐藏表示,在本文中具体为 Graph WaveNet 对 的输出表示。 最终,通过回归层预测未来的时间序列:
损失函数
综合考虑预测误差和图结构正则化,损失函数定义为:其中预测误差
通常采用平均绝对误差: 为预测的时间步数, 为时间序列的数量, 为通道数, 为权衡系数。
TSMixer(TMLR 2023)
TSMixer 的架构
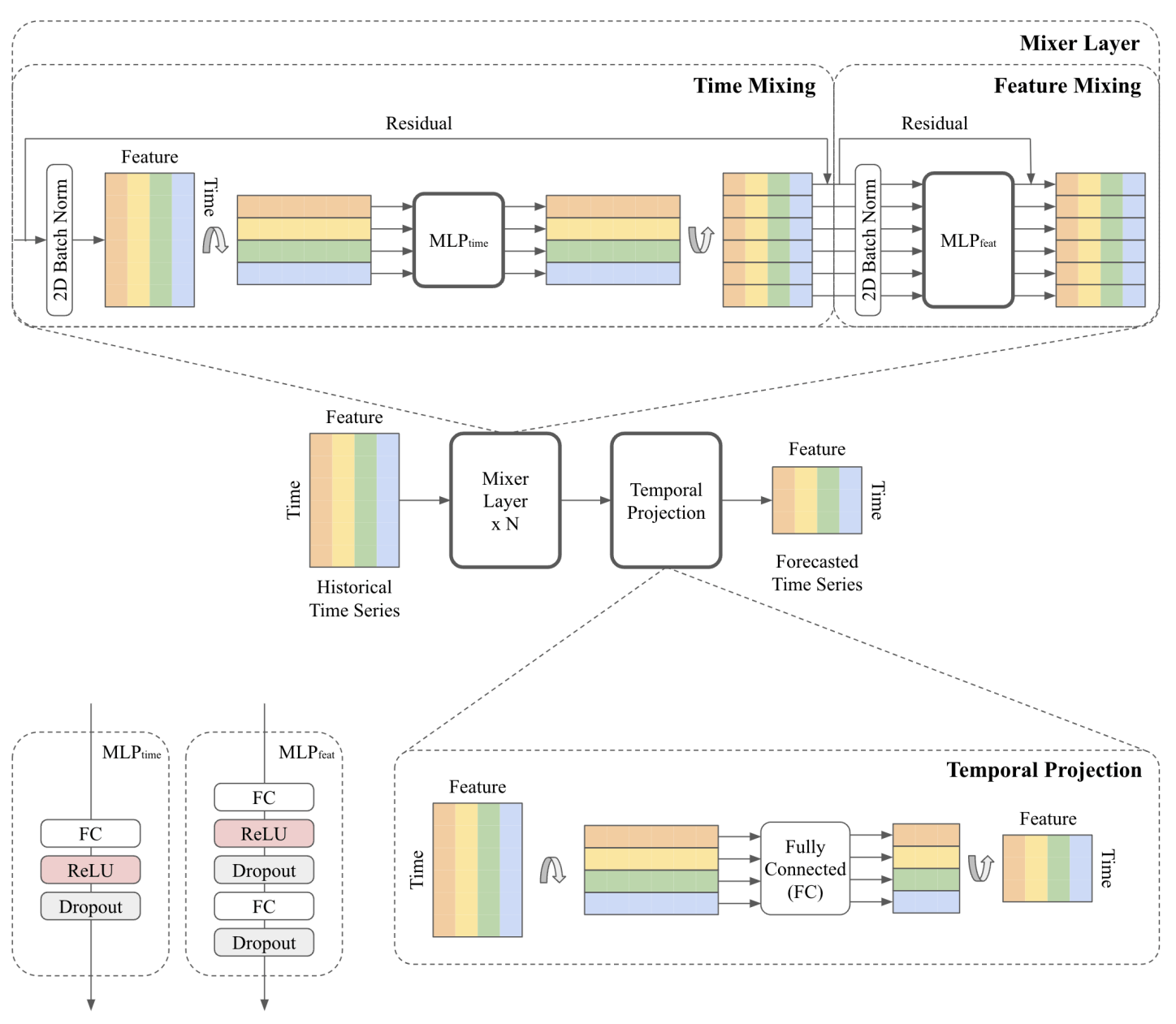
从上图中,我们可以看到该模型主要由两个步骤组成:混合层和时间投影。
- 混合层
对于时间混合,MLP 由全连接层、ReLU 激活函数和 dropout 层组成。
输入(其中行代表时间,列代表特征)被转置,以便 MLP 应用于时域并在所有特征之间共享。该单元负责学习时间模式。
在离开时间混合单元之前,再次对矩阵进行转置,并将其发送到特征混合单元。
特征混合单元由两个 MLP 组成。由于它应用于特征域,因此它在所有时间步之间共享。在这里,不需要转置,因为特征已经在水平轴上。
请注意,在两个混合器中,我们都有归一化层和残差连接。后者帮助模型学习更深层的数据表示,同时保持合理的计算成本,而归一化是改进深度学习模型训练的常用技术。
混合完成后,输出将发送到时间投影步骤。
- 时间投影
时间投影步骤是在 TSMixer 中生成预测的过程。
在这里,矩阵再次转置并通过全连接层发送以生成预测。最后一步是再次转置该矩阵,使特征位于水平轴上,时间步长位于垂直轴上。
TSMixer 的扩展架构
在某些时候,现实世界还允许使用未来的数据
(如未来的促销活动)或者静态数据 (如位置),这个时候需要融合这三方面的信息进行未来的预测。 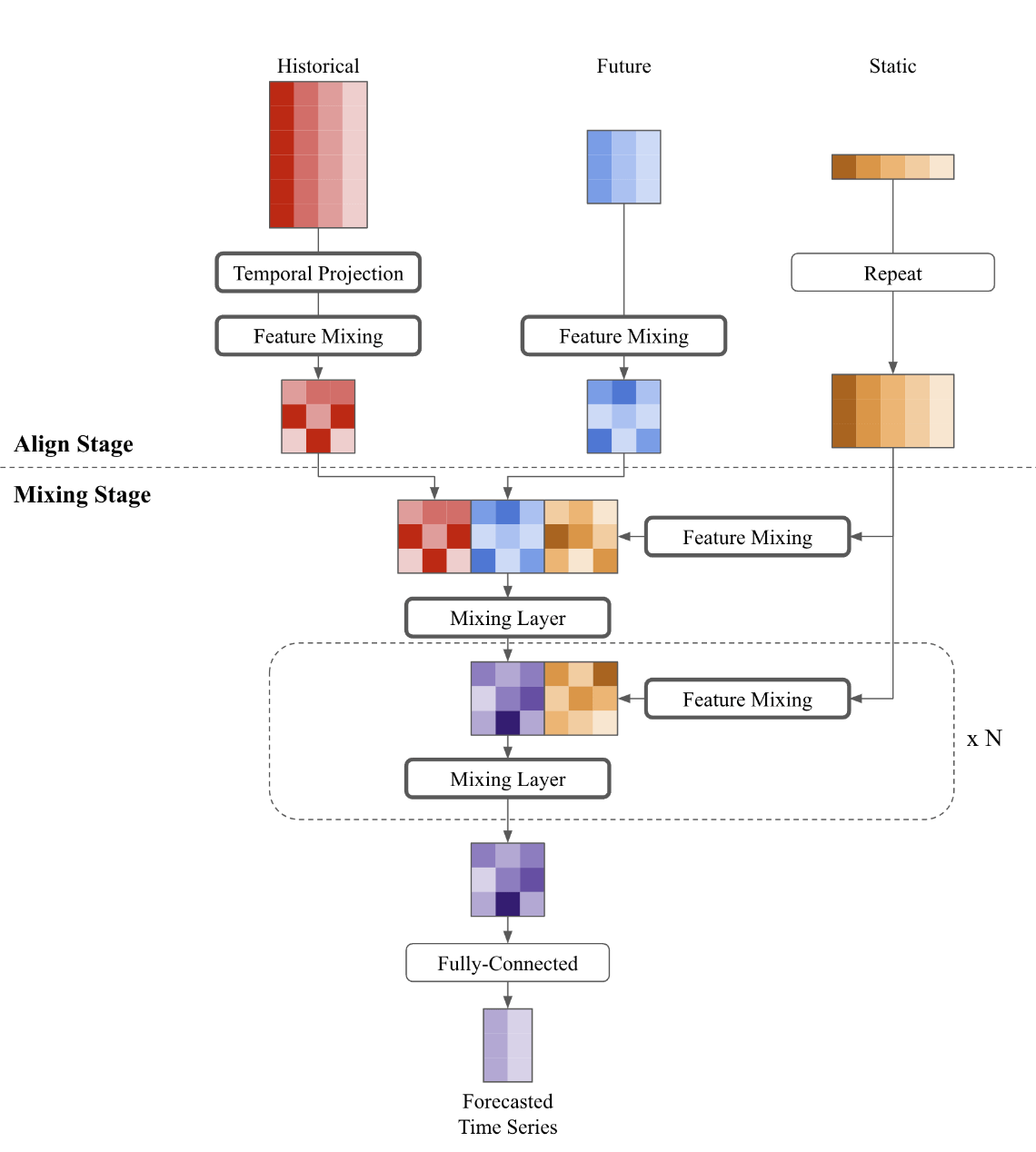
LARGE MODELS FOR SPATIO-TEMPORAL DATA
Spatio-Temporal Graphs
Large Language Models in Spatio-Temporal Graphs
Pre-Trained Foundation Models in Spatio-Temporal Graphs
Temporal Knowledge Graphs
暂时不关心这部分,待更新。
Videos
Large Language Models for Video Data
Valley
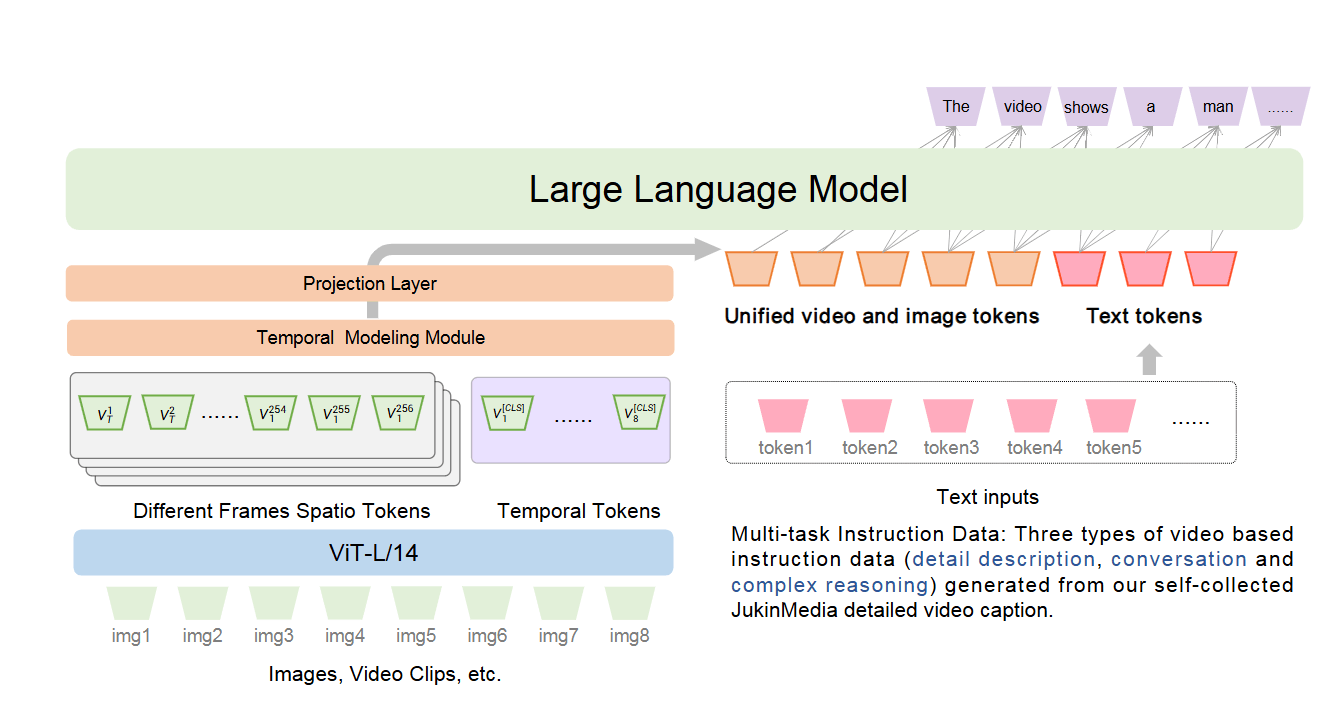
Valley 的整体架构包括:
- 大型语言模型(LLM):主要负责语言理解和生成。
- 视觉编码器:采用预训练的 ViT-L/14 模型,对输入的图像或视频帧进行特征提取。
- 时序建模模块:用于对视频帧的时序信息进行建模,生成统一的视觉特征表示。
- 投影层:将视觉特征映射到与 LLM 兼容的语言特征空间。
整个方法的流程如下:
输入处理
对于输入的视频或者图像,首先以一定的帧率从视频中采样得到
帧图像,表示为: 其中,
表示第 帧图像。 视觉特征提取
使用预训练的 CLIP 模型中的视觉编码器(ViT-L/14)对每一帧图像进行特征提取,得到每一帧的视觉特征:
每个视觉特征包含 256 个空间位置的 patch 特征和一个全局的 [CLS] 特征,表示为:
时序建模
为了整合不同时间帧的视觉特征,作者设计了三种时序建模策略,在这里统一表示为函数
。时序建模模块的输入是所有帧的空间特征,输出是聚合后的特征表示: 其中,
表示第 帧的空间特征。 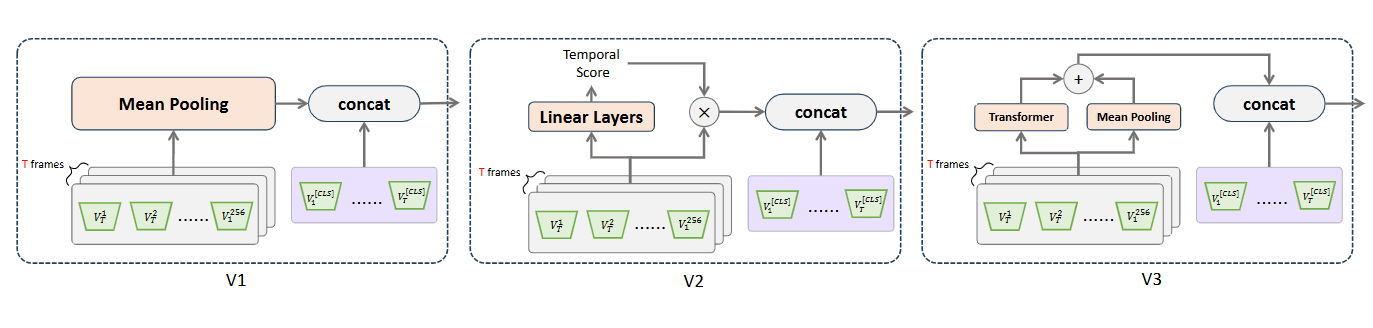
平均池化(v1)
第一种策略是对相同位置的空间特征在时间维度上进行平均:
其中,
表示第 个空间位置经过平均池化后的特征。 加权平均(v2)
第二种策略是引入一个可学习的线性层,用于学习每一帧在时间上的重要性得分,然后对空间特征进行加权平均:
Transformer 时序编码(v3)
第三种策略是使用一个 Transformer 编码器对每个空间位置的特征在时间维度上进行建模,以捕获时序变化信息:
生成统一的视觉特征表示
为了保留全局的时序信息,将经过时序建模的空间特征
与每一帧的全局 [CLS] 特征进行拼接,得到整个视频的视觉表示: 其中,
表示特征拼接操作。 特征投影
使用一个可训练的线性投影层,将视觉特征映射到与语言模型兼容的特征空间:
融合视觉和语言特征
将投影后的视觉特征和文本输入的词嵌入一起输入到大型语言模型中,进行多模态信息的融合和生成: 训练策略
为了使模型具备良好的视觉理解和指令跟随能力,作者采用了两阶段的训练策略:
第一阶段:预训练
在预训练阶段,只训练投影层,使得视觉特征能够被 LLM 理解:- 使用图像-文本对和视频-文本对进行训练,包括 595K 的 CC3M 图像-文本对和过滤后的 702K WebVid2M 视频-文本对。
- 构造单轮对话,将图像和视频描述作为回答,输入模型进行训练。
第二阶段:指令微调
在第二阶段,训练投影层和 LLM,以提升模型的指令跟随能力:- 使用作者构建的 73K 视频指令数据集,以及 LLaVA 的 150K 图像指令数据和 VideoChat 的 11K 视频指令数据,共计 234K 的多模态指令跟随数据进行训练。
- 冻结视觉编码器的参数,只训练投影层和 LLM 的全参数。
Pre-Trained Foundation Models for Video Data
mPLUG-2