

论文发布日期:2022.4.18
论文发表会议:CVPR
Abstract
- 联合嵌入已经成为了过去工作解决跨膜态检索问题的主要方法。
- 尽管联合嵌入很有效,它还是受到长期存在的"hubness problem"的影响,少量的gallery embeddings会形成许多查询的最近领域。
- 提出了Querybank Normalisation (QB-NORM)框架,它重新标准化查询相似度以充分考虑嵌入空间的中心。QB-NORM使得无需重新训练就可提高检索性能。
- 还提出了一种新颖的相似性归一化方法,Dynamic Inverted Softmax,比现有方法更加稳健。
Introduction
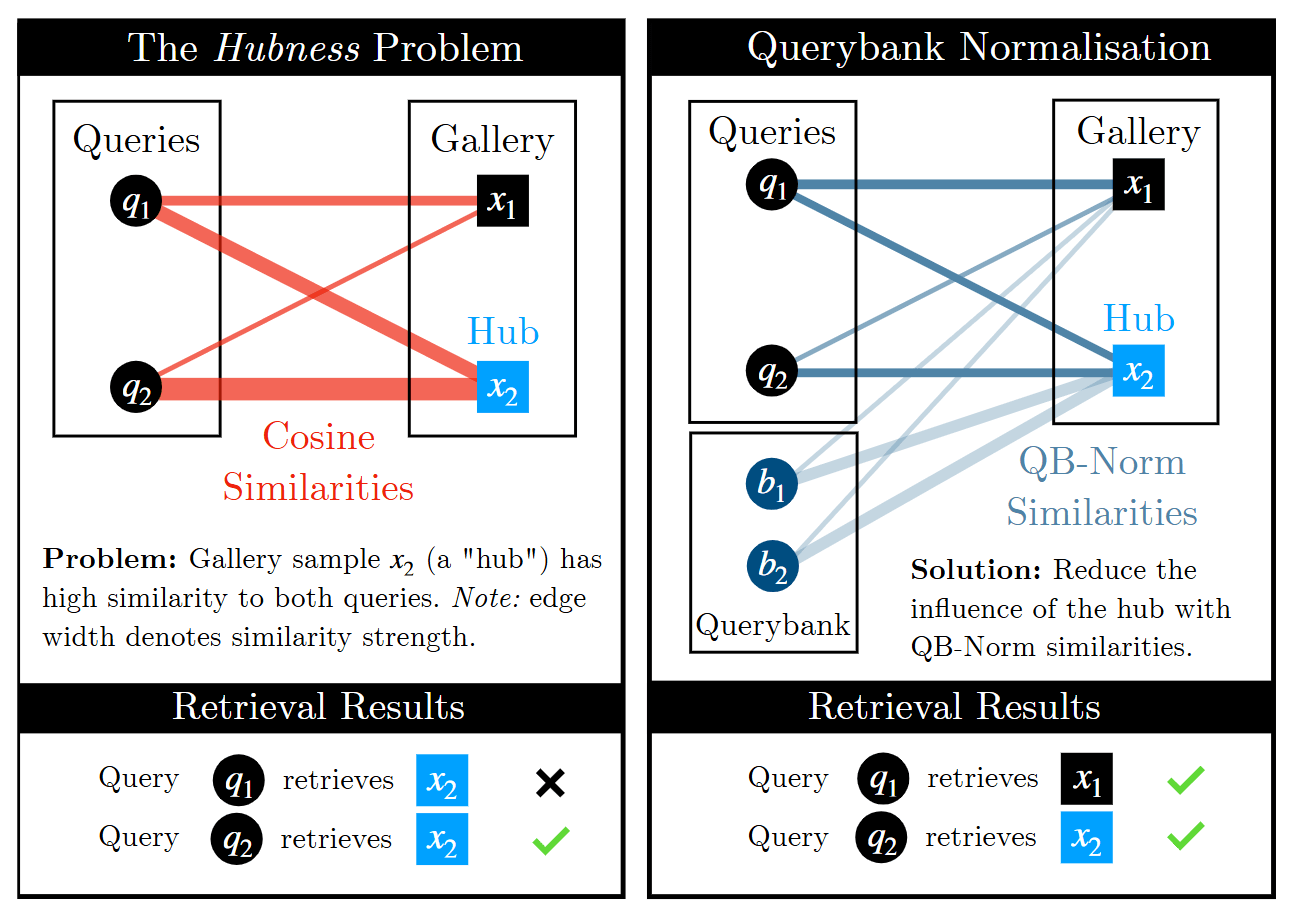
目标
如何减轻跨模态检索中高维联合嵌入会导致的Hubness Problem。
动机
- 目前跨模态检索使用的联合嵌入方法,容易导致Hubness Problem。即在高维嵌入空间中,少数几个样本(称为中心)会成为大量查询的最近邻,导致检索质量下降。
方案
- 提出了一种简单而有效的框架,称为查询库归一化(Querybank Normalisation,简称QB-NORM),旨在通过重新归一化查询相似度来减轻嵌入空间中的枢纽影响。QB-NORM无需重新训练模型,并且在不需要同时访问测试集的查询的情况下有效。
- 提出了一种新的相似度归一化方法——动态反向Softmax(Dynamic Inverted Softmax,简称DIS),其在鲁棒性上显著优于现有方法。
贡献
- 证明了长期存在的hubness问题是一个影响现代跨膜态嵌入检索的重要问题。
- 提出了QB-NORM方法,一个简单的非参数框架,可在不需要模型微调情况下显著提高检索性能。
- 证明了Querybank Normalisation方法保留了跨模态检索的有效性,使其无法越过当前的查询与其他查询产生联系。
- 提出了Dynamic Inverted Softmax,是一种新颖的查询库标准化方法,比之前的工作更稳健。
Cross-modal representations
早期的跨模态检索框架包括高斯混合模型(Gaussian Mixture Models)、主题模型(Topic Models)、典型相关分析(CCA)及其扩展方法、排名优化等。近年来,深度度量学习和深度视觉语义嵌入的成功,推动了文本-图像、文本-视频、文本-音频等多种跨模态嵌入方法的快速发展。
Similarity Search for Retrieval: Tricks of the Trade
为了支持和增强相似度搜索,研究人员开发了包括k-d树、重新排序、查询扩展、基于二进制码的向量压缩方案和量化方法等多种技术,以应对高维空间中的“维度灾难”。
Memory bank augmented architectures
各种形式的memory banks已经成为神经网络架构的有效扩展,在解决一般问题、改进图像captioning、增强自监督训练动态等方面展示了其价值。本文提出的QB-NORM框架同样使用了外部记忆库,旨在减轻嵌入空间中的Hubness Problem。
The Hubness Problem
Hubness Problem在高维嵌入空间中普遍存在,其特征是少数几个样本频繁出现在多个查询的最近邻集合中。这一问题最早由Radovanovic等人提出,他们观察到在具有高内在维度的分布中,“k-出现次数”(k-occurrences)的分布严重向右偏斜。尽管对于Hubness Problem的成因存在不同观点,但其通常与高维空间中的距离集中现象相关,即高维空间中的点通常位于以数据均值为中心的超球面上,彼此之间的距离相似。
Hubness Mitigation
缓解Hubness Problem方法主要分为以下几类:
- 重缩放相似度空间(Rescaling the Similarity Space):
- 局部缩放(Local Scaling):根据每个查询的邻域信息调整相似度。
- 全局缩放(Global Scaling):基于整个嵌入空间的统计信息调整相似度。
- 处理聚类中心(Handling Centroid Hubs):
- 使用拉普拉斯基函数(Laplacian-based Kernels)或中心化(Centering)方法减少聚类中心作为枢纽的倾向。
- 跨域方法(Cross-domain Methods):
- 在零样本学习(Zero-Shot Learning)中,通过将(文本)目标映射回(图像)查询空间,或通过最小化枢纽性相关的代理指标来缓解枢纽性。
- 在自然语言处理(NLP)中,通过跨域局部缩放(Cross-Domain Local Scaling, CSLS)或反向Softmax(Inverted Softmax, IS)等方法,改善不同语言词典间的翻译质量。
Method
Task definition
给定一个模态中的样本库(Gallery)
用于定义“良好匹配”的相似性度量的选择由应用领域决定。例如,在使用自然语言查询的文本-视频检索任务中,目标是根据视频内容被书面自由文本查询描述的程度对视频库进行排序,而在图像-音频检索中,目标通常是从库中获取与图像查询具有相同语义类别的音频样本。
在这项工作中,特别关注使用自然语言查询的跨模态检索任务,原因有二:
- 这些任务在hubness mitigation相关文献中受到的关注有限。
- hubness problem在高内在维度的嵌入中尤其普遍。由于自然语言查询可以表达比单个词更复杂的概念(例如在零样本学习图像标注任务中考虑的那些),期望自然语言查询能够自然地引入具有更大内在维度的跨模态嵌入,从而可能更有潜力从hubness mitigation中受益。
Motivation
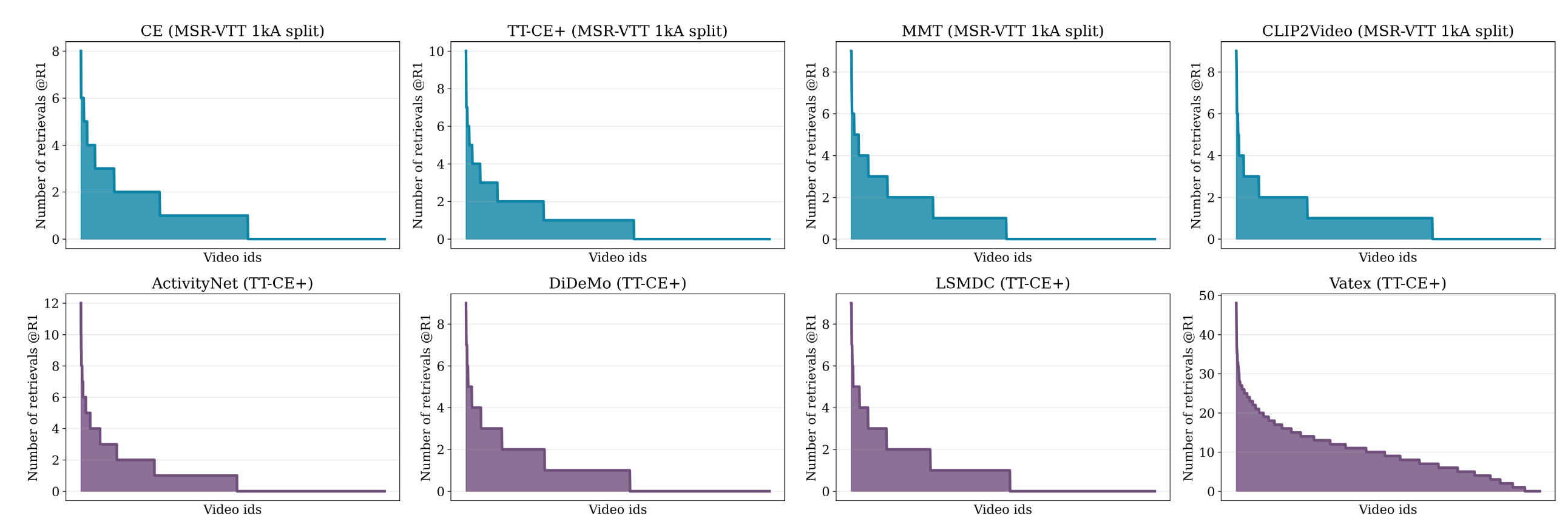
长期以来,人们观察到高维嵌入空间容易出现hubness现象,即少数样本在所有嵌入的
为说明这一问题,考虑使用自然语言查询的视频检索问题。作者绘制了在MSR-VTT检索基准上,每个库视频被检索次数的分布,涉及一系列文本-视频检索方法,包括CE、TT-CE+、MMT和CLIP2Video,还有TT-CE+方法在各个数据集下的检索分布,包括ActivityNet、DiDeMo、LSMDC和Vatex等。
在每种情况下,都看到了hubness现象的明显证据——少数视频被极其频繁地检索,而其他视频则完全没有被检索到。这种现象不限于特定的检索模型,表明该问题不能通过使用多种视频模态、注意力机制和大规模预训练的各种组合来轻易解决。
Querybank Normalisation

在过去的文献中,作者特别感兴趣的是那些可以应用于实际跨模态检索设置的方法,即这些方法的复杂度至多与库的大小呈线性关系(而不是寻求在固定嵌入空间内解决hubness问题的二次复杂度方法)。
为明确现有方法之间的关系,作者将它们放入查询库归一化框架,该框架包括两个组件:查询库构建和相似度归一化,具体描述如下:
查询库构建:为了减缓跨模态嵌入空间中的枢纽现象,希望以减少hubness影响的方式改变嵌入之间的相似度。为调整相似度,首先从查询模态
相似度归一化:为了归一化相似度以考虑枢纽问题,我们假设可以访问一个查询
在实践中,用于相似度归一化的探测矩阵可以预先计算并在所有查询中重复用(提高计算效率,但代价是更高的内存)。
Design choices
查询库归一化框架在查询库构建和相似度归一化方面提供了多种可行选择。为说明这一点,我们首先将NLP文献中提出的三种hubness mitigation技术纳入该框架,然后介绍我们提出的替代方法:the Dynamic Inverted Softmax。
Globally-Corrected (GC) retrieval:最初用于双语翻译和零样本学习任务,这种方法可以通过从完整的测试查询集合
其中
Cross-Domain Similarity Local Scaling (CSLS):为双语词汇翻译任务引入,CSLS构建一个包含所有可能查询的初始查询库(对应于源词汇样本),然后使用查询库的不同子集来归一化每个库样本。令
Inverted Softmax (IS):针对双语词汇翻译,这种方法从源词汇(对应于所有可能感兴趣的查询)中构建查询库。对于实际应用,作者建议均匀随机地子采样一个可行数量的查询。相似度归一化通过以下方式实现:
其中
Dynamic Inverted Softmax (DIS):在上述方法的实验中,我们观察到一个重要的实际问题:如果查询库不能有效覆盖包含库的空间,性能会严重下降。为了应对这一问题,除了上一节算法流程图中描述的查询库探测矩阵外,我们还预先计算一个库激活集:
这里,符号
由于
Experiments
Datasets and Evaluation Metrics
在多个标准基准数据集上进行了实验,包括:
- 文本-视频检索:MSR-VTT、MSVD、DiDeMo、LSMDC、VaTeX、QuerYD
- 文本-图像检索:MSCoCo
- 文本-音频检索:AudioCaps
- 图像-图像检索:CUB-200-2011、Stanford Online Products
评估指标主要包括:
- R@K(Recall at K):查询的正确结果在前K个检索结果中的比例,越高越好。
- MdR(Median rank):正确结果在检索列表中的中位数排名,越低越好。
Querybank Normalisation
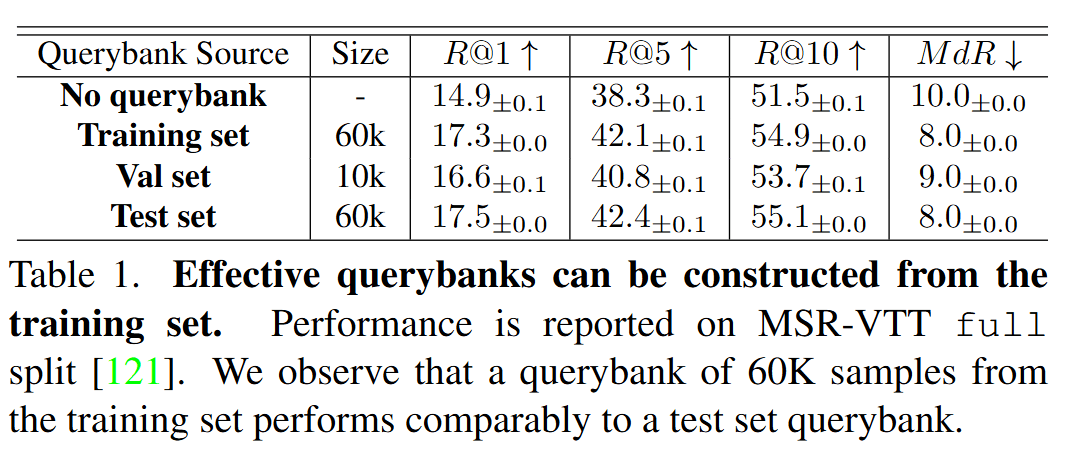
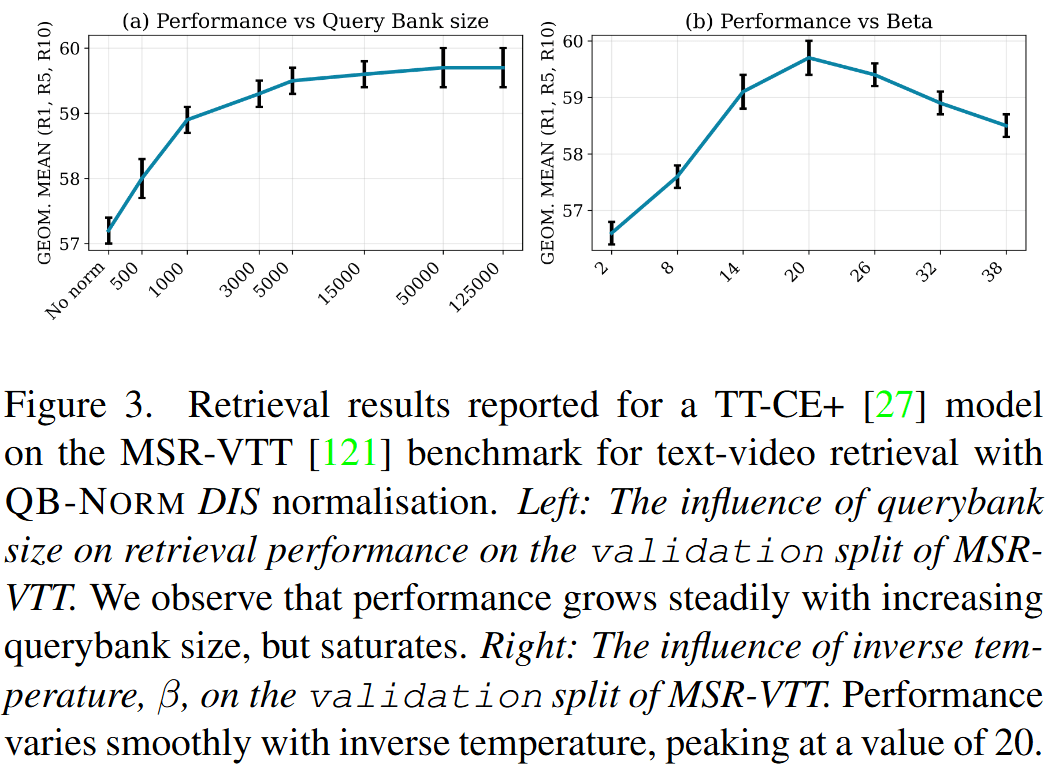
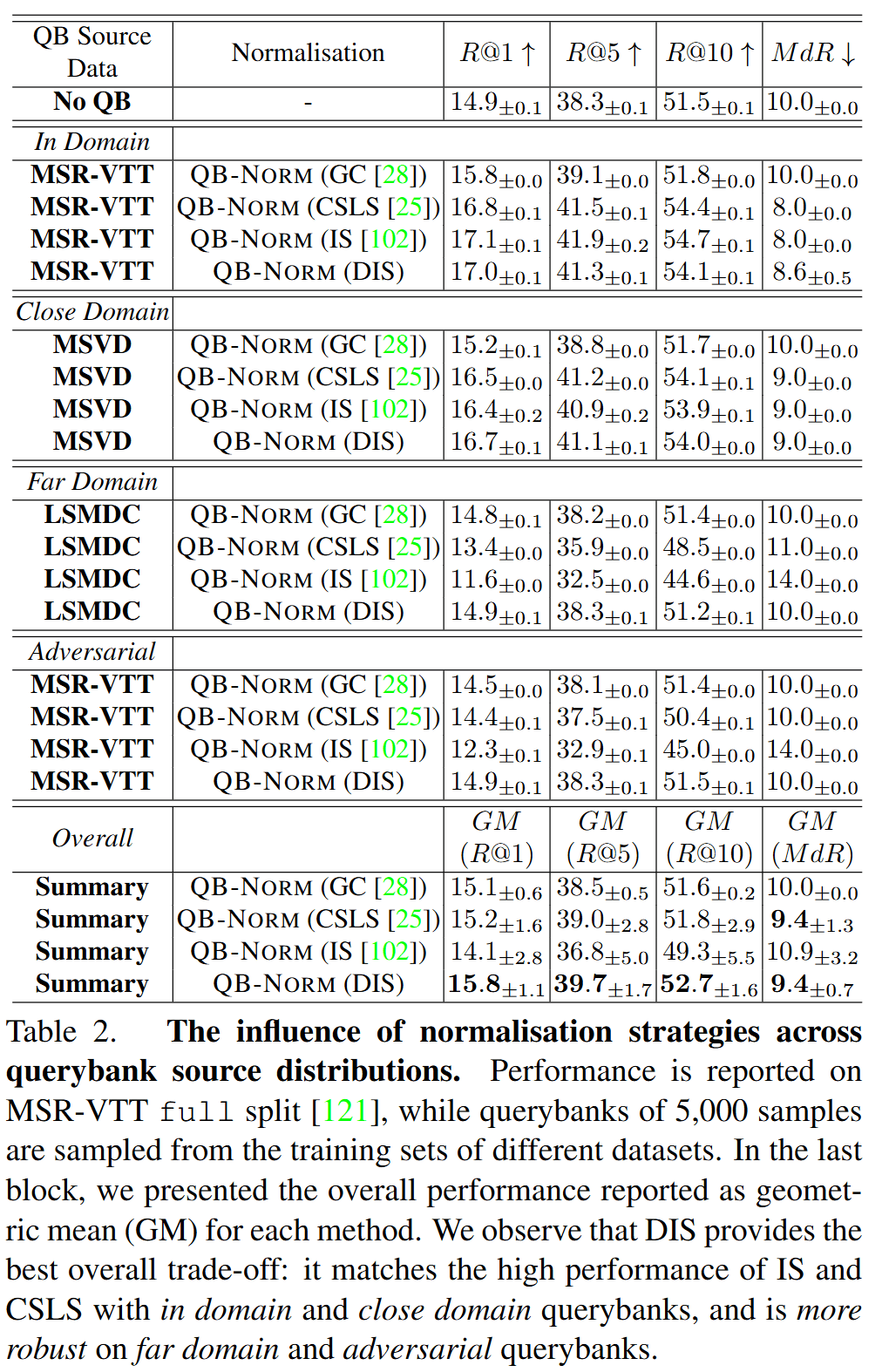

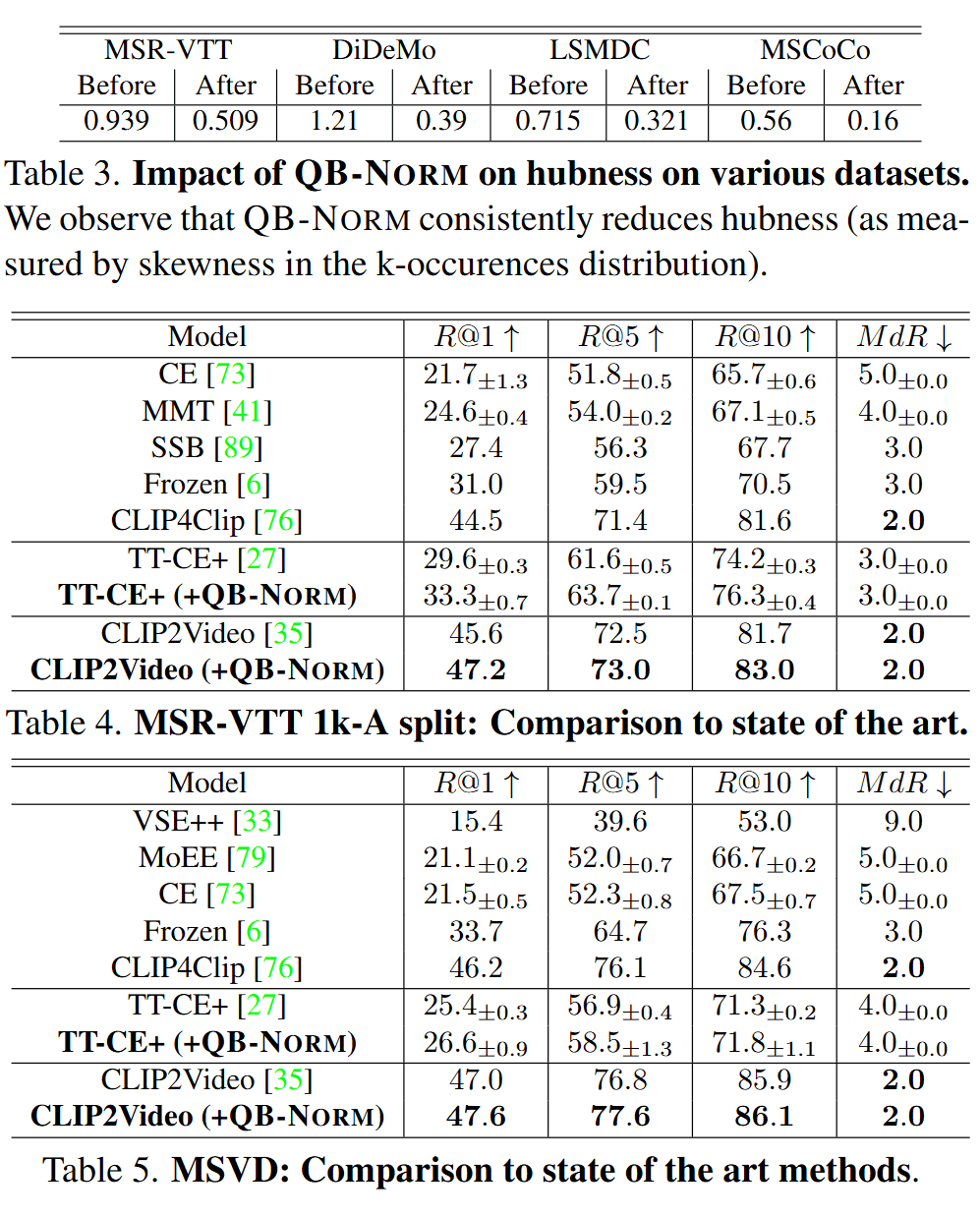
Comparison with other methods
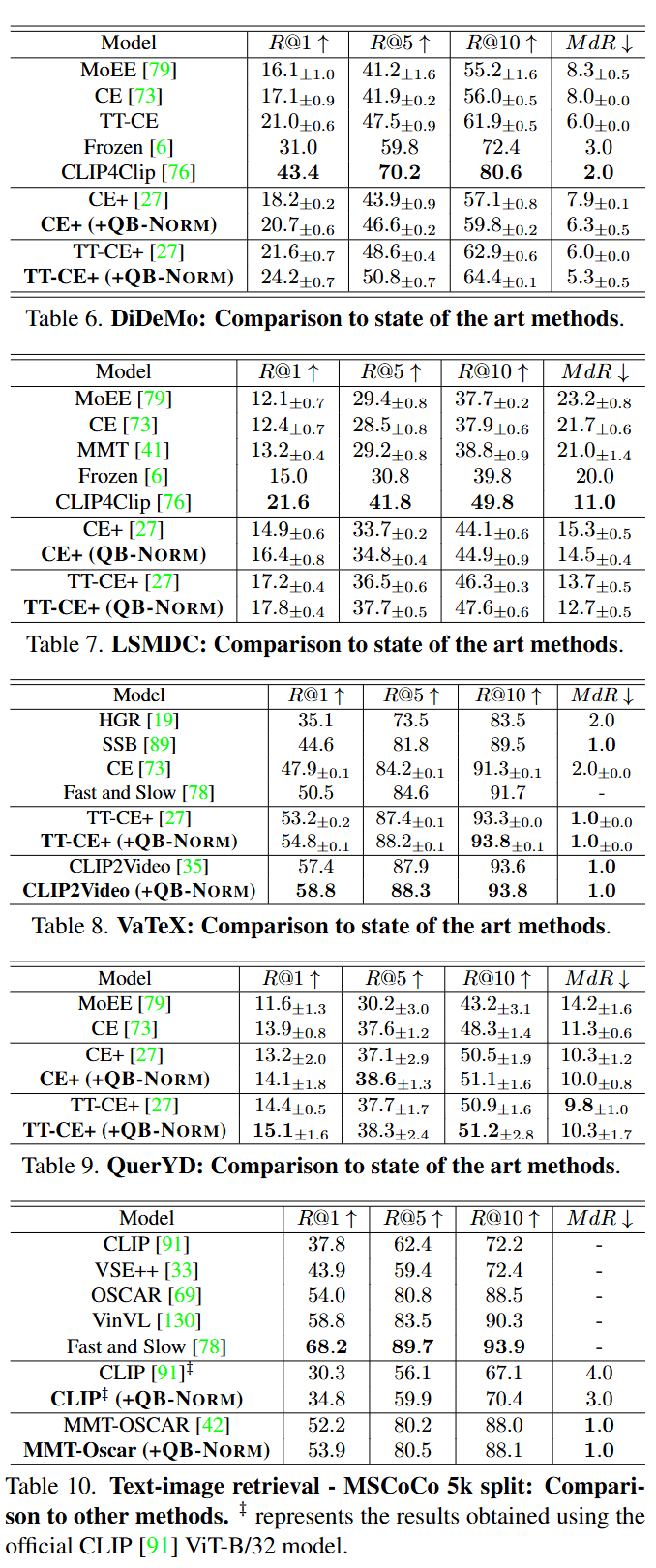
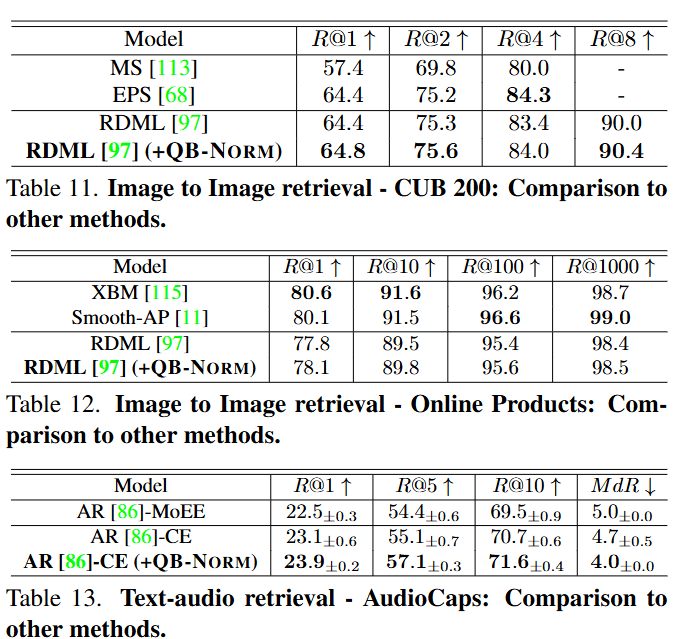
Limitations and societal impact
Limitations
使用QB-NORM的所有归一化技术都会产生额外的预计算成本。我们提出的归一化技术DIS,相较于其他归一化方法增加了一些额外的计算成本。而且不利的查询库选择和显著的领域差距会降低查询库归一化的效益。
Societal impact
跨模态检索是一种强大的工具,既有积极的应用,也有潜在的风险。跨模态搜索可以为研究人员、音乐家、艺术家和消费者提供高效的内容发现。然而,这一能力也可能被用作政治压迫的工具:例如,它可能使社交媒体内容的高效搜索成为可能,以发现政治异议的迹象。
Conclusions
- 引入了用于Hubness Mitigation的查询库归一化框架。
- 提出了Dynamic Inverted Softmax (DIS)用于稳健的相似度归一化。
- 展示了其在多种任务、模型和基准中广泛的适用性。