

论文发布时间:2023.5
论文发布会议:NeurIPS
Abstract
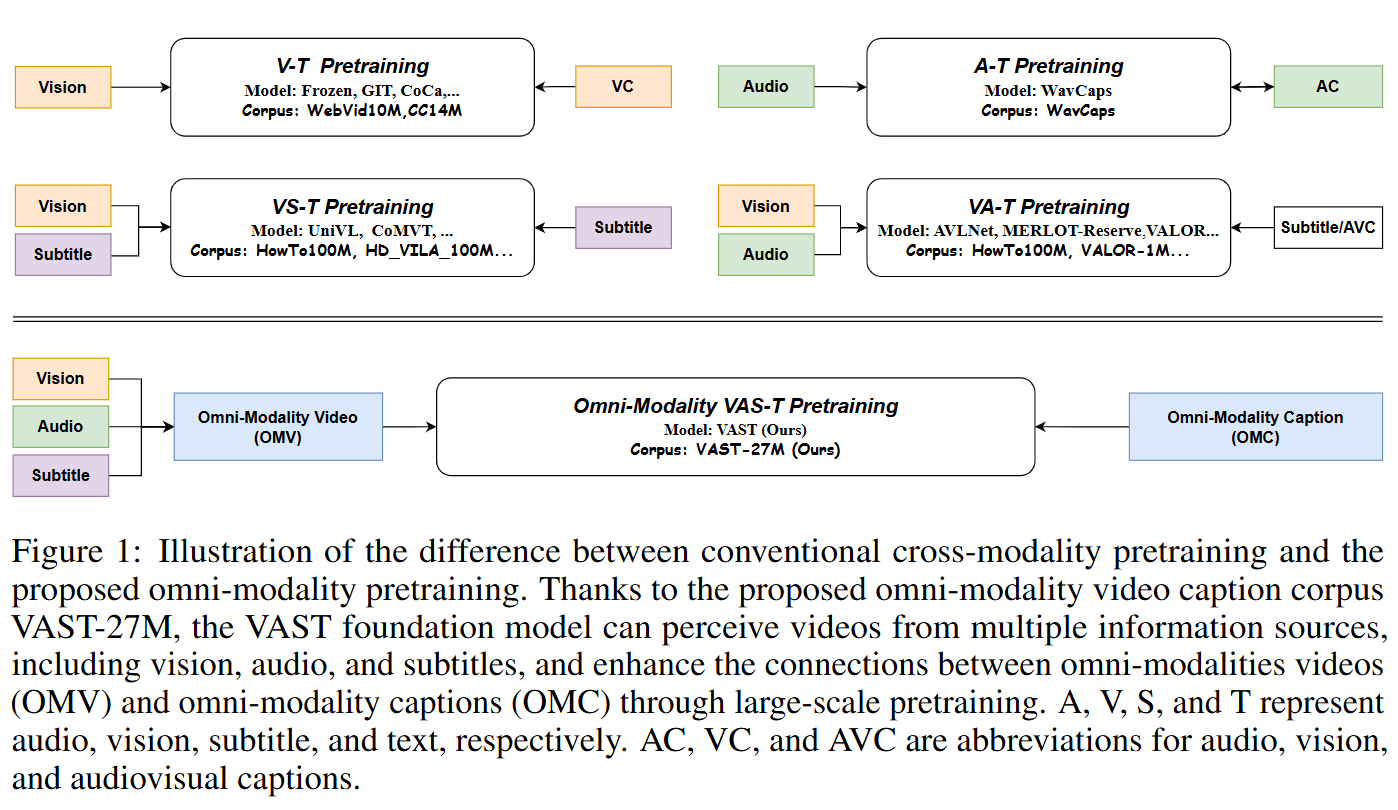
- 该论文旨在探索视频中的多模态(视觉、音频、字幕)与文本之间的联系,弥补现有视频-文本模型在音频和字幕等模态上的不足。
- 作者收集了2700万个开源视频片段,并分别训练视觉和音频描述生成器来生成视觉和音频的描述。接着,利用预训练的大型语言模型(LLM)将生成的视觉、音频描述与字幕及指令prompts整合,生成全模态的视频描述,从而构建了名为VAST-27M的大规模全模态视频描述数据集。
- 基于VAST-27M数据集,作者训练了名为VAST的全模态视频-文本基础模型,该模型能够感知和处理视频中的视觉、音频和字幕模态,从而支持视觉-文本、音频-文本及多模态视频-文本任务(包括检索、描述生成、问答等)。通过大量实验,作者证明了VAST-27M数据集和VAST模型的有效性,VAST在多个跨模态基准上取得了22项新的最先进成果。
Introduction
目标
如何通过跨模态学习(特别是视频和文本的结合)来训练大模型更好地理解视频内容。这包括视频字幕生成、视频检索和视频问答等任务。
动机
- 现有的视频-文本预训练模型主要局限于视觉和文本之间的关联,忽视了音频、字幕等其他关键信息。为了提高模型的预测能力,需要融入更多模态信息(如音频和字幕)。
- 缺乏训练语料库,训练全模态模型需要一个全模态视频字幕语料库,其中字幕需要同时表现出与视觉、音频和字幕的对应性。现有数据集要么只包含字幕或视觉音频描述等,没有包含全模态的。

方案
- 为了解决大规模全模态数据集的缺乏,使用了一种两阶段的自动pipeline生成全模态描述,并结合大语言模型生成高质量的全模态字幕,创建了VAST-27M数据集。
- 在公开的视觉音频字幕语料库上训练单独的视觉和音频字幕生成器模型。
- 利用Vicuna-13b这个现成的大模型,将单模态字幕、普通字幕和指令prompt输入,鼓励它总结为一个长句子形成全模态caption。
- 数据集最后包含11个字幕(5个视觉,5个音频和一个全模态)。
- 提出了一种全模态预训练模型,即VAST(Vision-Audio-Subtitle-Text),采用了VAST-27M数据集。这个数据集包含视频、音频、字幕和文本的多模态信息。
- 包含三个单模态编码器,使用文本编码器通过交叉注意力层实现跨模态融合。
- 三个训练目标OM-VCC、OM-VCM、OM-VCG,有效增强全模态能力。
- 能有效支持广泛的下游任务,能够感知4种模态
贡献
- 提出了VAST-27M,这是第一个大规模全模态视频字幕数据集,自动生成自单模态字幕生成器和大语言模型。
- 训练了第一个基于视觉、音频、字幕和文本的全模态基础模型(VAST),实现了全模态感知和理解。
- VAST模型在多种跨模态任务中超越了现有模型,在多个benchmarks中达成SOTA。
Cross-Modality Pretraining Corpus
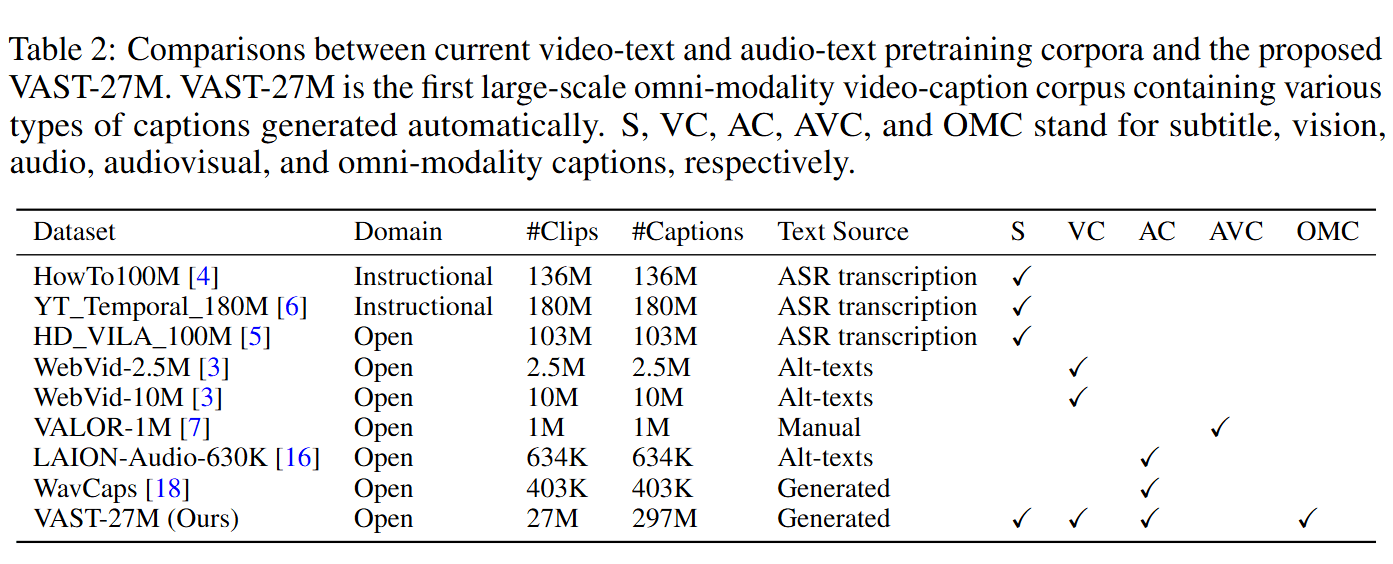
Video-Text Pretraining Corpus(视频-文本预训练语料库)
- 早期工作:早期的视频-文本模型大多在大规模的 HowTo100M 数据集 上进行训练,该数据集包含1.22百万YouTube教学视频,使用自动生成的字幕作为文本描述。然而,这些字幕通常与视觉内容的相关性较低。
- 其他数据集:
- YT-Temporal-180M 数据集:包含了180百万个从6百万个YouTube视频中提取的片段,进一步扩展了视频和字幕的规模。
- HD_VILA_100M 数据集:包含100百万个视频片段,字幕通过自动生成减少了人工标注的成本,但字幕与视频内容的相关性仍然有限。
- WebVid10M 数据集:使用替代文本(alt-texts)作为视频字幕,这些文本虽然与视频内容更相关,但风格与标准字幕不同,且没有整合其他模态(如音频)。
- VALOR-1M 数据集:包含带有注释的音视频内容,但规模较小且难以扩展,主要由于人工标注的高成本。
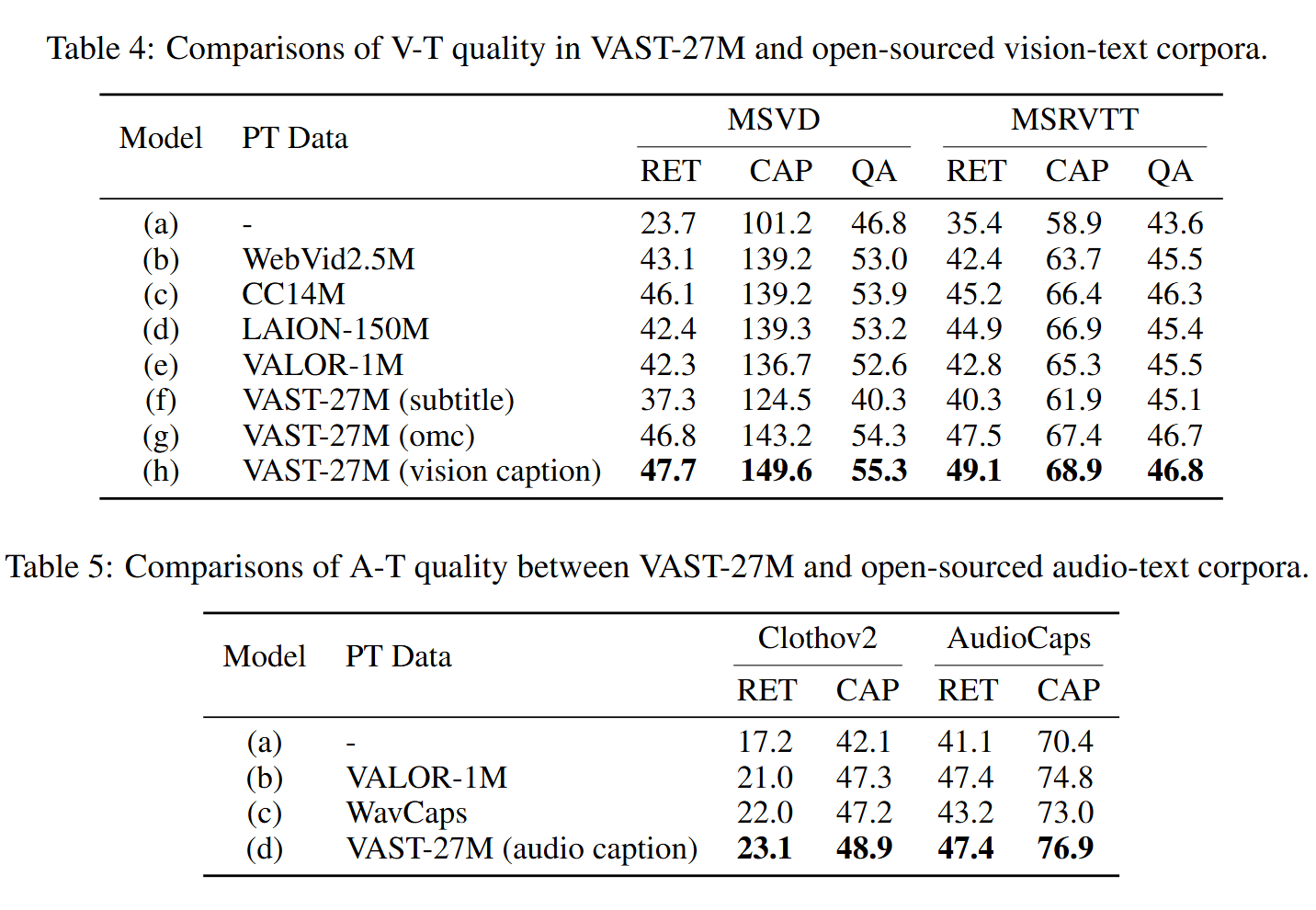
- VAST-27M 的贡献:VAST-27M 是第一个涵盖视频、音频和字幕的高质量大规模全模态视频字幕数据集。通过自动生成管道,其生成成本相比手动标注更加经济高效,且涵盖了所有模态的信息。
Audio-Text Pretraining Corpus(音频-文本预训练语料库)
- 进展较慢的原因:与视频-文本预训练相比,音频-文本预训练由于语料库规模和质量的限制,进展相对较慢。现有的音频数据集(如 Clotho 和 AudioCaps)包含的音频数据较为有限(少于50,000个音频片段),难以满足大规模预训练的需求。
- 其他数据集:
- LAION-Audio-630K:该数据集包含跨多个来源爬取的音频及替代文本,音频大多来自Freesound平台,但质量参差不齐。
- WavCaps 数据集:包含403,000个音频片段,描述使用了ChatGPT生成,但生成的描述质量受限,存在噪声。
- VAST-27M 的贡献:与之前的音频-文本语料库相比,VAST-27M 通过高质量的单模态字幕生成器生成音频字幕,质量和规模都显著提升,几乎比 LAION-Audio-630K 和 WavCaps 大两个数量级。
Multi-Modality Learning
早期探索
- MMT:MMT方法通过结合多个专家模型,提升了文本到视频检索的效果。
- SMPFF:该方法引入了音频模态,用于视频字幕生成任务。
视频-文本预训练中的多模态方法
一些工作开始将字幕或音频与视觉和文本一起联合建模,代表性模型包括:
- UniVL
- CoMVT
- VALUE
这些模型中,字幕与文本的关联性较弱且隐含,通常通过 masked prediction 或 next utterance prediction 来实现,使用的是原始字幕作为预测目标,而不是抽象的文本。这种方法在预训练和微调阶段之间引入了不一致性。
VAST:VAST模型充分利用了大语言模型的泛化能力,能够从字幕中提取最关键信息并生成语言描述,解决了字幕与文本之间关联性弱的问题。
音频的引入
- 音频模态的联合建模:
- 代表性的工作包括 AVLNet、MERLOT Reserve、i-Code 和 VALOR。这些模型将音频模态与其他模态结合,但主要侧重于学习 音频-字幕的关系,而非音频-文本的关系。
- 局限性:
- AVLNet、MERLOT Reserve 和 i-Code 主要用于任务如文本到音频检索和音频字幕生成,难以泛化到其他任务。
- VALOR 虽然联合建模了音频、视觉和文本,但更多关注环境音效而非人类语音。
- VAST的突破:与上述方法不同,VAST是第一个能够感知 视觉、音频、字幕和文本 四种模态的全模态基础模型,并实现了这四种模态与字幕生成的连接,具备更广泛的应用能力。
Dataset
Data Collection of VAST-27M
Vision Captioner Training
- 目标:建立物体与视觉概念之间的通用对应关系。
- 训练过程:
- 从 BLIP 模型获取灵感,首先在大规模图像-文本语料库上训练视觉字幕生成模型,使用的数据集包括 CC4M、CC12M 和从 LAION-400M 随机选择的1亿对图像-文本对。
- 随后,在组合的手动标注图像和视频字幕数据集上进行微调,包括 MSCOCO、VATEX、MSRVTT 和 MSVD。
- 通过此过程,模型能够同时感知静态物体和动态动作,生成高质量、流畅且准确的字幕。
Audio Captioner Training
- 训练数据:音频字幕生成模型使用 VALOR-1M 和 WavCaps 数据集进行训练。
- 与视觉生成器的不同:与视觉字幕生成不同,音频字幕生成没有进行第二阶段的微调,因为现有的音频字幕数据集规模有限,进行微调可能会导致模型过拟合到狭窄的音频概念。
- 数据集保障:VALOR-1M 是一个带有人工标注的语料库,提供了对字幕准确性的基本保证。
Clip Selection
- 出于下载、存储和计算成本的考虑,从 HD_VILA_100M 数据集中选择了27M个视频片段,而不是使用所有数据。
- 选择规则包括:
- 丢弃时长小于5秒或长于30秒的片段。
- 丢弃缺少视觉、音频或字幕模态的片段。
- 从原始3.3M长视频中均匀选择片段。
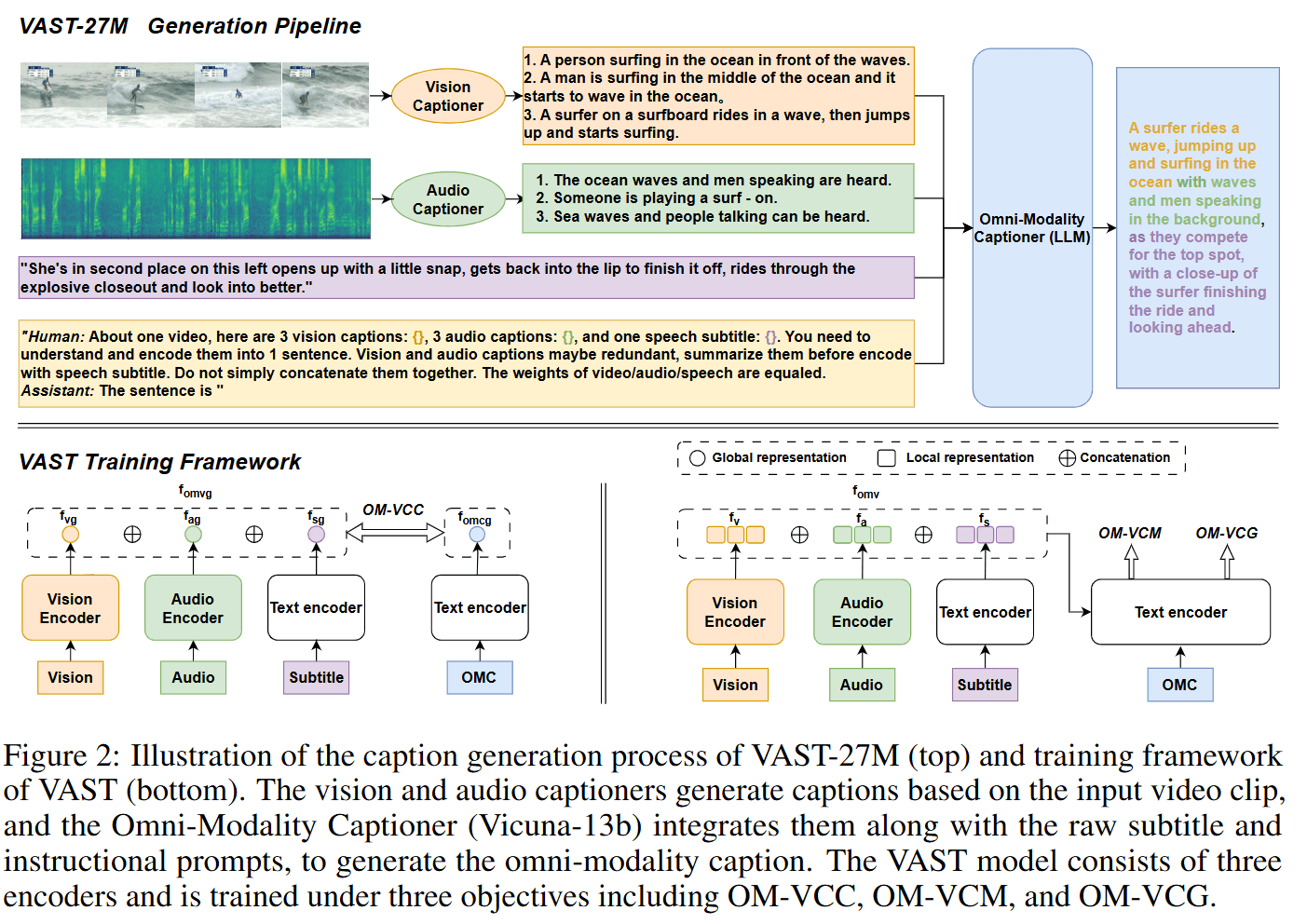
Caption Generation
- 生成过程:
- 对于VAST-27M的每个视频片段,使用训练好的视觉和音频字幕生成器,采用 Top-K 采样策略(K=10),为每个视频生成5个字幕。
- 接着,使用开源的 Vicuna-13b 模型作为全模态字幕生成器,Vicuna-13b 是一个基于Transformer架构的大语言模型,通过微调 LLaMA 模型进行训练。
- 具体操作:
- 对于每个视频片段,随机选择3个视觉字幕和3个音频字幕,加上原始字幕和设计好的提示,输入到大语言模型中。
- 大语言模型生成全模态字幕,这些字幕能够有效描述视觉、音频和字幕内容,并且符合自然的人类字幕风格。
Statistics of VAST-27M
- 数据规模:VAST-27M 包含 27M 个从大型 HD_VILA_100M 语料库中抽取的视频片段。
- 类别覆盖:数据集涵盖超过 15个类别,包括音乐、游戏、教育、娱乐、动物等,不是仅限于教学领域的 HowTo100M 数据集。
- 字幕数量:VAST-27M 包含大量字幕,涵盖了多模态(视觉、音频、全模态)和字幕数量方面的广泛内容。
- 字幕平均长度:
- 视觉字幕:平均长度为 12.5。
- 音频字幕:平均长度为 7.2。
- 全模态字幕:平均长度为 32.4。
Approach
Basic Framework
如图 2 所示,VAST 采用了一个完全端到端的 Transformer 架构,包含视觉编码器 (ViT)、音频编码器 (BEATs) 和文本编码器 (BERT)。该框架可以处理多模态输入,如图像、视频、音频、字幕和描述。文本编码器负责编码单模态的描述或字幕,并通过交叉注意力层执行多模态编码/解码。
- 全模态描述和字幕通过 WordPiece tokenizer进行分词,然后输入到文本编码器中,分别得到输出特征
和 。 - 视觉编码器以原始图像或稀疏采样的视频帧作为输入,并产生输出特征
。 - 对于音频片段,首先将其分成多个 10 秒长的片段,使用零填充,转换为 64 维的对数 Mel 滤波器组频谱图,使用 25ms 的 Hamming 窗口处理后,输入到音频编码器中,得到输出特征
。 - 这些特征的全局表示([CLS] token 特征)分别记为
、 、 和 。
Pretraining Objectives
Omni-Modality Video-Caption Contrastive Loss (OM-VCC)
全模态视频片段的全局表示,记为
Omni-Modality Video-Caption Matching Loss (OM-VCM)
该损失鼓励模型推断一对 OMV 和 OMC 是否匹配。具体来说,字幕标记输入到文本编码器中,此时通过激活交叉注意力层来关注条件特征
Omni-Modality Video Caption Generation Loss (OM-VCG)
该损失使用条件因果掩码语言建模来增强模型生成全模态字幕的能力。具体来说,OMC 中 60% 的标记在文本编码器输入端被掩盖。交叉注意力层被激活,
Overall loss
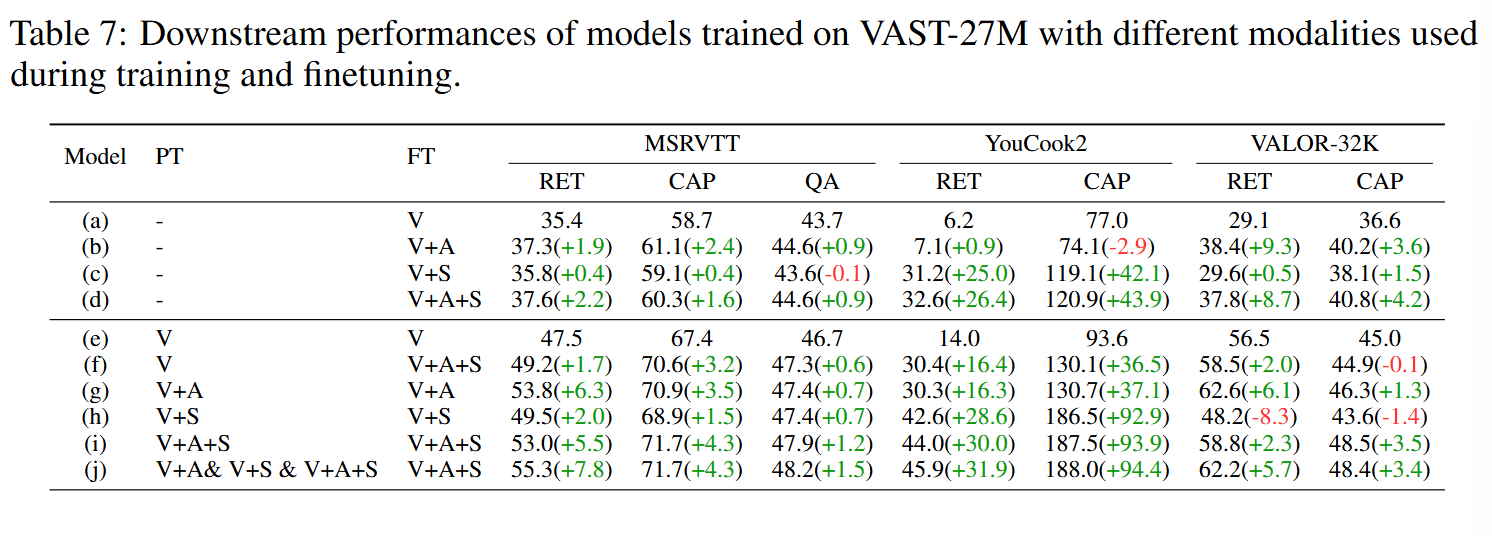
Modality Grouping
虽然 VAST 在预训练期间建立了全模态视频-字幕的对应关系,但在下游基准测试和实际应用中,必须解决模态缺失的潜在问题,因为预训练和应用过程中模态之间的不一致可能会产生负面影响。受到 VALOR 提出的模态分组策略的启发,作者分组不同模态统一建模了 V-T、A-T、VA-T、VS-T 和 VAS-T(刚刚介绍的为
Experiments
Implementation Details
训练框架与硬件
- VAST 模型使用 PyTorch 框架在 64 张 Tesla V100 显卡上进行训练。
- 视觉、音频和文本编码器分别初始化为 EVAClip-ViT-G 、BEATs 和 BERT-B,模型总参数量为 13B。
训练数据与语料库
- 训练语料库是多个数据集的组合:
- VAST-27M
- VALOR-1M
- WavCaps
- CC14M
- 110M 随机采样的 LAION-400M 配对数据
- 训练步数为 200k:
- 每一步训练时,随机从上述语料库中选择一个进行训练。
- CC14M 和 LAION 的原始描述被训练好的视觉描述生成器替换。
训练参数
- 初始学习率:
- 学习率衰减策略:线性衰减。
- 批量大小:1024。
- 在每个预训练步骤中,视频片段中随机采样 1 帧,音频片段中随机采样 2 个 10 秒长的音频片段。
消融实验
- 消融实验中使用了 CLIP-ViT-B作为视觉编码器,并冻结其参数。
下游任务适配
- 检索任务:所有候选项使用 VCC 进行初步排序,然后使用 VCM 对前 50 名候选项重新排序。
- 字幕生成任务:使用 Beam Search,束宽为 3。
- 问答任务:设置为开放式生成任务,问题作为前缀,答案无约束地生成。
评估指标
- 检索任务:Recall@1
- 字幕生成任务:CIDEr
- 问答任务:Accuracy (Acc)
详细的预训练数据集混合比例和下游任务微调配置在附录中。
Comparison to State-of-the-Art Models
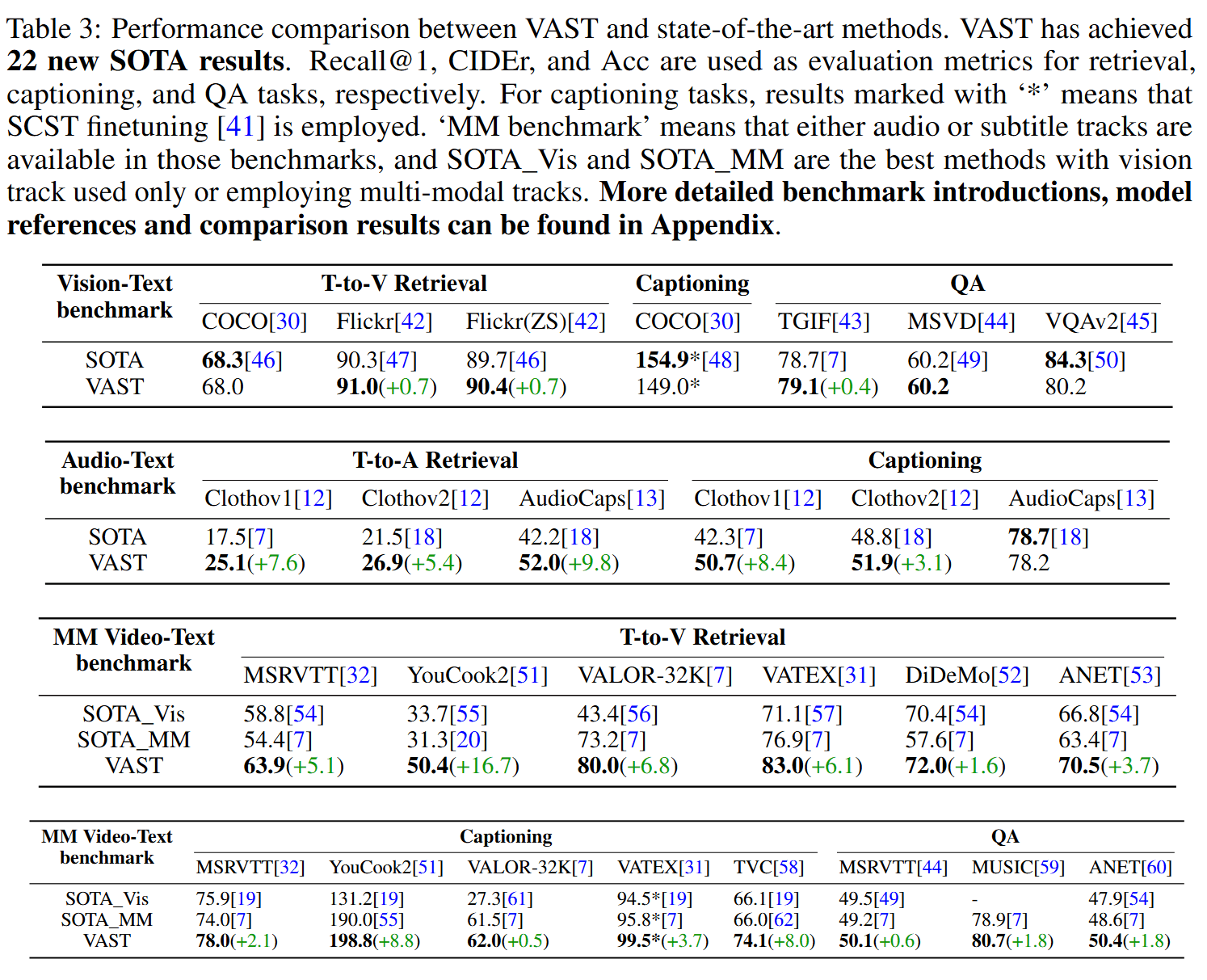
Comparison to Open-Source Cross-Modality Training Corpus
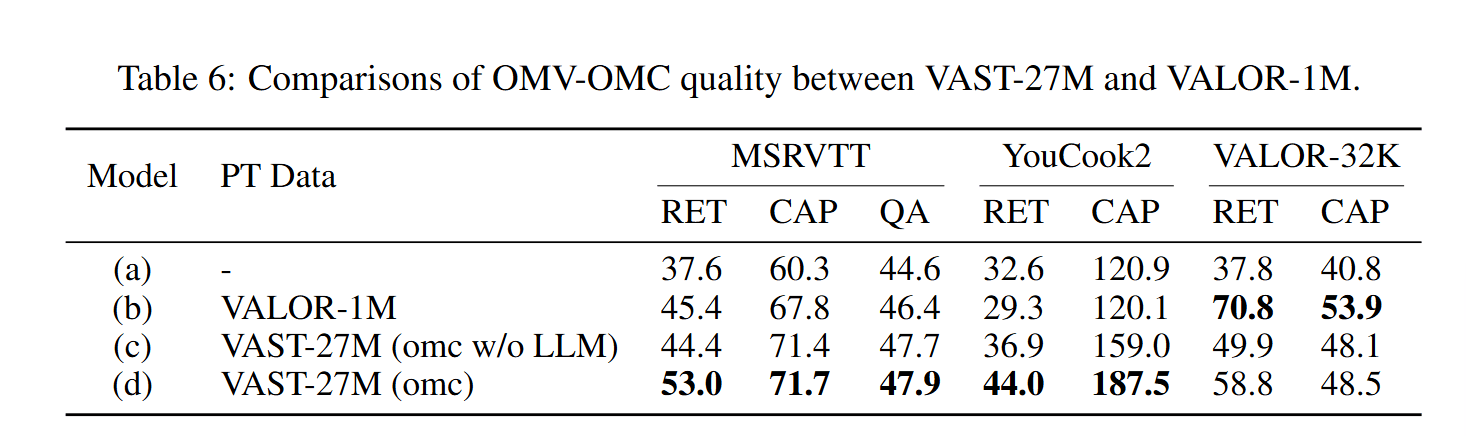
Ablation Study
Conclusion, Broader Impact and Limitation
Conclusion
- VAST-27M 语料库:
- 介绍了 VAST-27M,一个大规模的全模态视频描述数据集,旨在推动多模态预训练的研究。
- 数据集中每个视频片段都配有自动生成的视觉和音频描述,以及通过预训练的大型语言模型(LLM)整合视觉、音频和字幕生成的全模态描述。
- VAST 模型:
- 训练了一个统一的基础模型 VAST,能够理解并连接视频中的各种模态信息(视觉、音频、字幕)与描述。
- VAST 展现了其在视觉-文本、音频-文本、多模态视频-文本任务(如检索、字幕生成、问答等)中的有效性,实现了SOTA。
Broader Impact
- 多模态理解的影响:
- 多模态视频内容的理解在多个领域(如娱乐、教育、安全、交通、医疗等)具有重要影响。
- VAST-27M 和 VAST 这样的全模态基础模型的发展,有助于推动这些领域的进展和实际应用。
- 潜在应用:
- 全模态模型能在多种实际应用中发挥重要作用,如自动视频内容生成、视频检索、多模态翻译等,推动娱乐和教育领域的变革。
- 在医疗和安全领域,这类模型有助于解读复杂的多模态数据,有助于更快更准确的决策。
Limitation
- 语料库的多样性:
- 需要更多样化和更大规模的全模态数据集来进一步提升模型的泛化能力,VAST-27M 语料库虽然规模较大,但仍不足以覆盖所有多样化的模态场景。
- LLM 的集成:
- 虽然 VAST 已经能够支持多种下游任务,但为了进一步提升其泛化能力,集成 大型语言模型(LLM) 是必要的。然而,LLM 的集成可能并未完全消除模型在多模态任务中的局限性。
- 数据偏差:
- VAST-27M 的数据采集和视频、音频描述的生成过程中依赖了 LLM 和一些开源的跨模态语料库,这些语料库和模型可能存在数据偏差,导致 VAST-27M 数据集和 VAST 模型可能受到这些偏差的影响。