

论文发布时间:2024
Abstract
- 视频内容在时间上连续,事件之间通常缺乏清晰的界限。这种边界模糊性使得模型学习文本视频片段对应关系变得具有挑战性,导致现有方法在预测目标片段方面性能不佳。
- 为了缓解上述问题,提出了从去噪生成角度联合解决视频时刻检索和高光检测两个任务,通过diffusion从粗到细的迭代细化,可以清晰定位目标边界。
- 提出了一种新颖的框架DiffusionVMR,结合扩散模型将这两个任务重新定义为统一条件的去噪生成过程。框架的训练和推理过程是解耦的,推理无需与训练保持一致。
INTRODUCTION
问题
- 如何解决视频模态的事件边界模糊性问题。
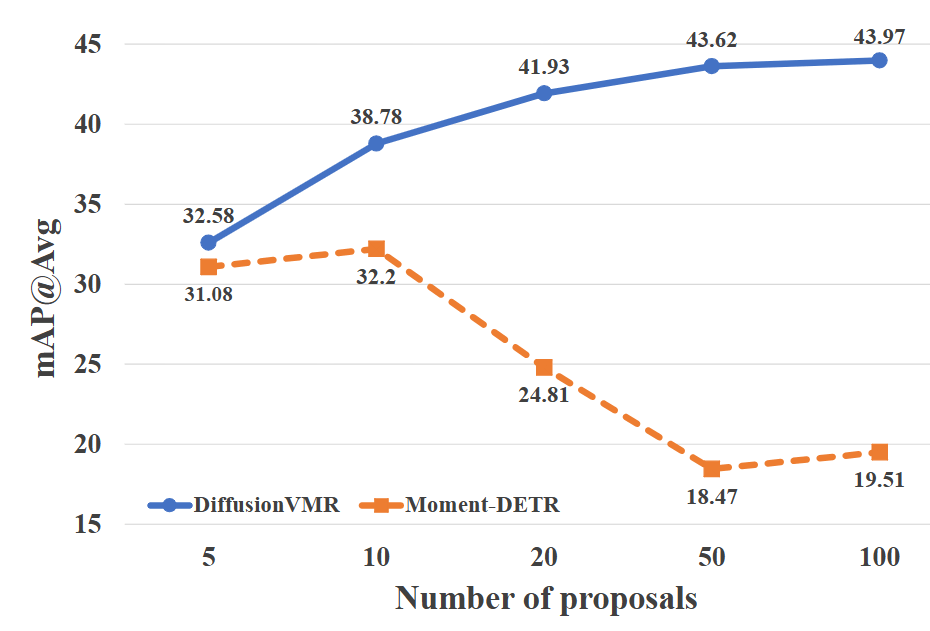
- 如何克服视频时刻检索任务中有proposal方法的空间问题,直接预测边界并达到同样效果。
- 如何结合视频时刻检索和高光检测两个任务,利用它们的强内在联系。
动机
- 视频是时间连续的,具有边界模糊性。
- 视频时刻检索和高光检测两个任务具有内在的联系,一个是根据查询定位视频片段的边界,一个是根据查询定位与查询主旨最相关的片段、生成显著性分数。
- diffusion可以从粗到细迭代去噪,慢慢清晰定位目标边界,揭示查询、视频和事件边界间的联系。
方案
两个分支,一个时刻检索,一个高光检测。
- 时刻检索分支包含跨模态编码器执行视频文本交互,输出相似性感知条件(视频文本融合表示)。时刻去噪解码器包含多个去噪层,每一层根据查询视频融合表示和噪声跨度作为输入更新。
- 高光检测分支仅包含显著性去噪解码器。生成反应查询和视频片段之间相关性的显著性得分。
APPROACH
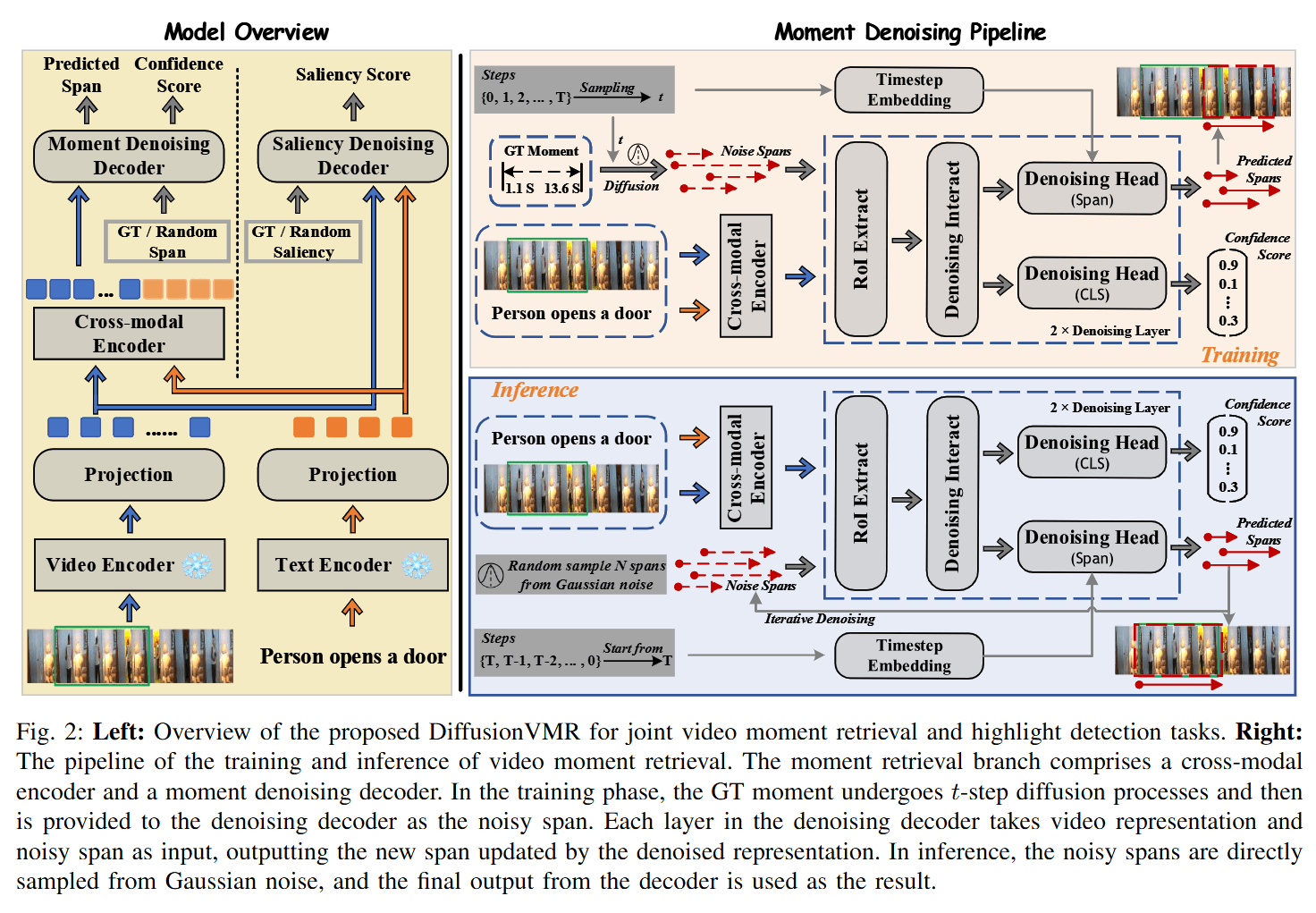
输入,从ground truth加入噪声并且通过随机生成事件跨度,填充某些视频数量不够的span,保证标签数量的一致性。
时刻检索分支,先融合文本视频模态,然后输入噪声span和时间步,利用RoI alignment先抽取文本视频对应关系特征,然后输入去噪网络,包含多个transfomer块。推理时直接生成随机噪声span。
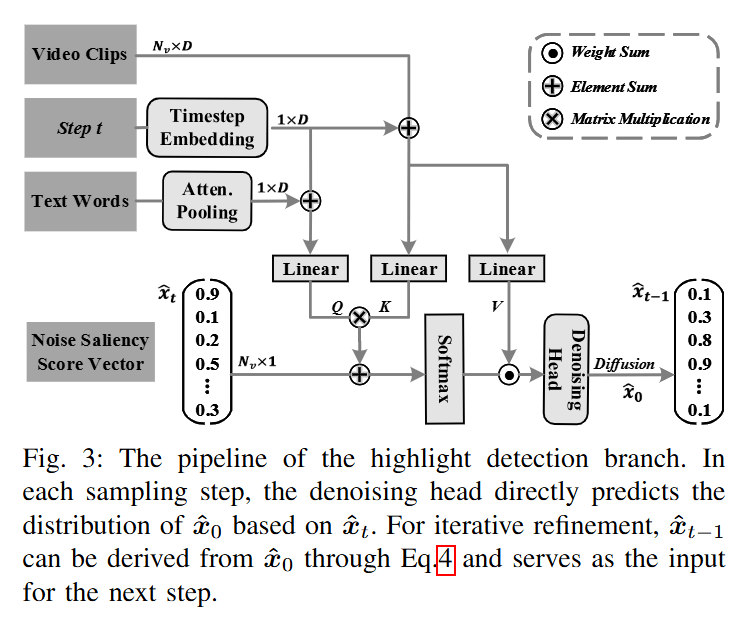
高光检测分支,类似DiffusionRet中的去噪网络,如图所示。
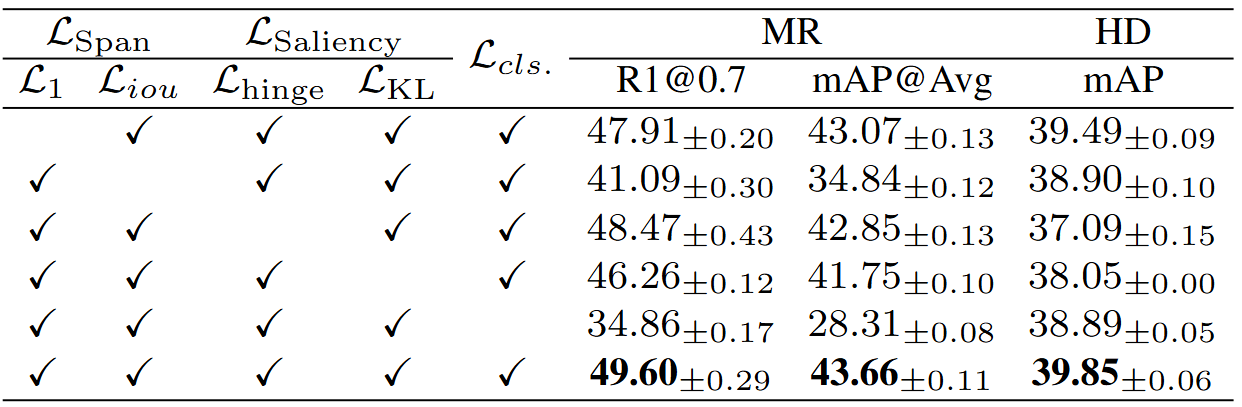
损失函数
总体损失函数定义为多个子损失的加权和,具体公式如下:
其中:
-
-
-
-
具体子损失的组成
分类损失
用于区分预测的片段是否为前景(即与查询相关的目标片段)或背景。采用交叉熵损失(Cross-Entropy Loss)来衡量预测类别与真实类别之间的差异:其中,
是预测的置信度分数。 片段损失
用于衡量预测的时间跨度与真实时间跨度之间的误差。该损失由两部分组成:- L1 损失
:衡量预测的时间跨度中心点和宽度与真实值之间的绝对误差。
- IoU 损失
:衡量预测的时间跨度与真实时间跨度之间的交并比(Intersection over Union),用于评估预测和真实跨度的重叠程度。
其中,
通过匈牙利算法(Hungarian Algorithm)找到与第 个预测最优匹配的真实片段。 - L1 损失
亮点检测损失
用于优化每个视频片段的显著性评分,该损失由对比损失(Hinge Loss)和Kullback-Leibler散度(KL Divergence)组成:对比损失
:用于区分高显著性(与查询相关)的片段和低显著性(不相关)的片段。公式如下: 其中,
是一个边际值, 和 分别表示低显著性和高显著性片段的评分。 KL 散度损失
:用于衡量生成的显著性评分分布与真实显著性评分分布之间的差异,促进生成模型生成更接近真实分布的评分。
其中,
是真实的显著性评分向量, 是预测的显著性评分向量。 匹配策略
由于预测和真实片段之间的对应关系并非一一对应,因此引入了匈牙利算法来进行双边匹配,确保每个预测与最相近的真实片段进行匹配,避免不稳定的匹配过程,特别是在训练的早期阶段。匹配过程通过最小化匹配成本函数
来实现: 其中,
是一组预测, 是一组真实片段。
EXPERIMENTS
实验设置
- 实验环境:
- 实验使用 PyTorch 作为环境。
- 运行设备为 1×NVIDIA RTX 3090 GPU。
- 输入限制:
- 每个视频的输入帧数限制为 75 帧。
- 每个查询的输入文本限制为 32 个单词,超出的词会被截断。
- 模型架构:
- 跨模态编码器 包含 6 层自注意力层。
- 时刻去噪解码器 包含 2 层去噪层。
- 模型的隐藏维度设置为
。
- 训练设置:
- 模型训练 300 轮,选择验证集上表现最好的模型进行测试。
- 模型权重通过 Xavier 初始化 随机初始化。
- 优化器为 AdamW,初始学习率为
,权重衰减为 。 - 扩散最大步数
。
- 超参数设置:
- 损失函数的超参数设置:
: 损失的权重。 :IoU 损失的权重。 :分类损失的权重。 :显著性损失的权重。
- 损失函数的超参数设置:
- 提议生成:
- 训练时,提议数量从 1 逐渐增加到 20。
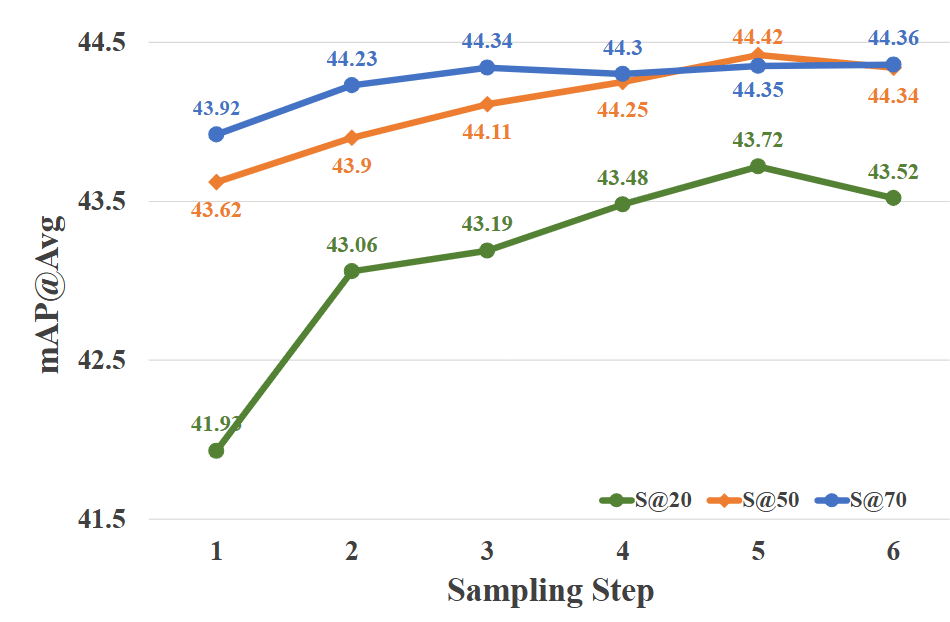
- 推理时,提议数量和采样步骤通过网格搜索策略确定。
- 数据集与特征:
- 使用的数据集及其特征:
- QVHighlights 数据集 :使用官方发布的 SlowFast 和 CLIP 特征。
- Charades-STA 数据集 :使用 SlowFast 和 CLIP 特征。
- TACoS 数据集 :使用 C3D 特征。
- TVSum 和 YouTube Highlights 数据集 :使用 SlowFast 和 CLIP 特征。
- VGG 特征用于 Charades-STA 数据集 。
- 使用的数据集及其特征:
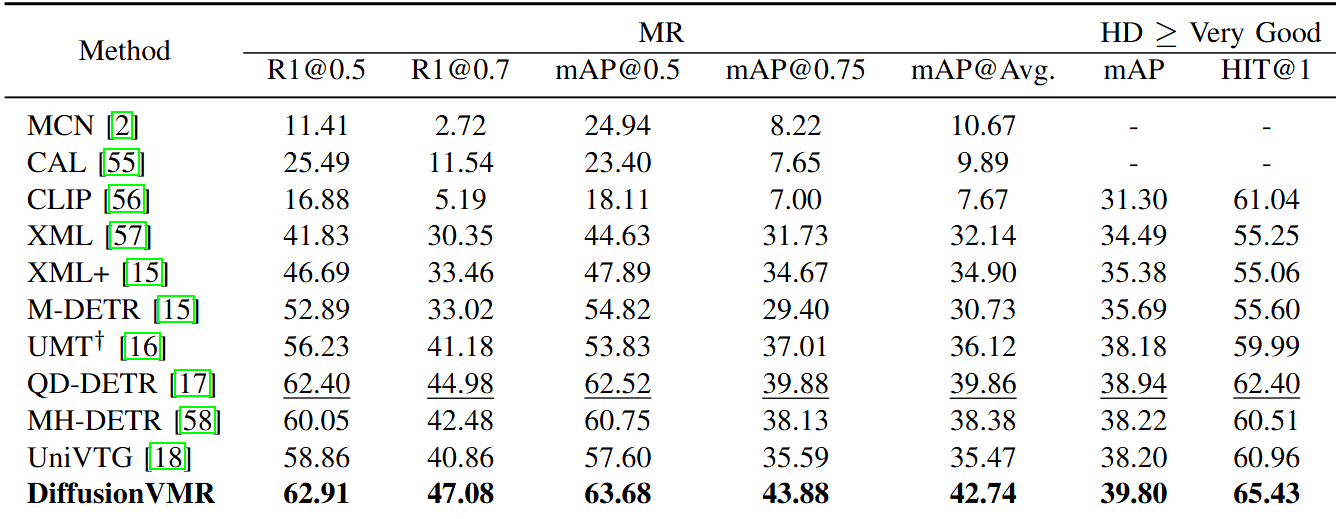
时刻检索
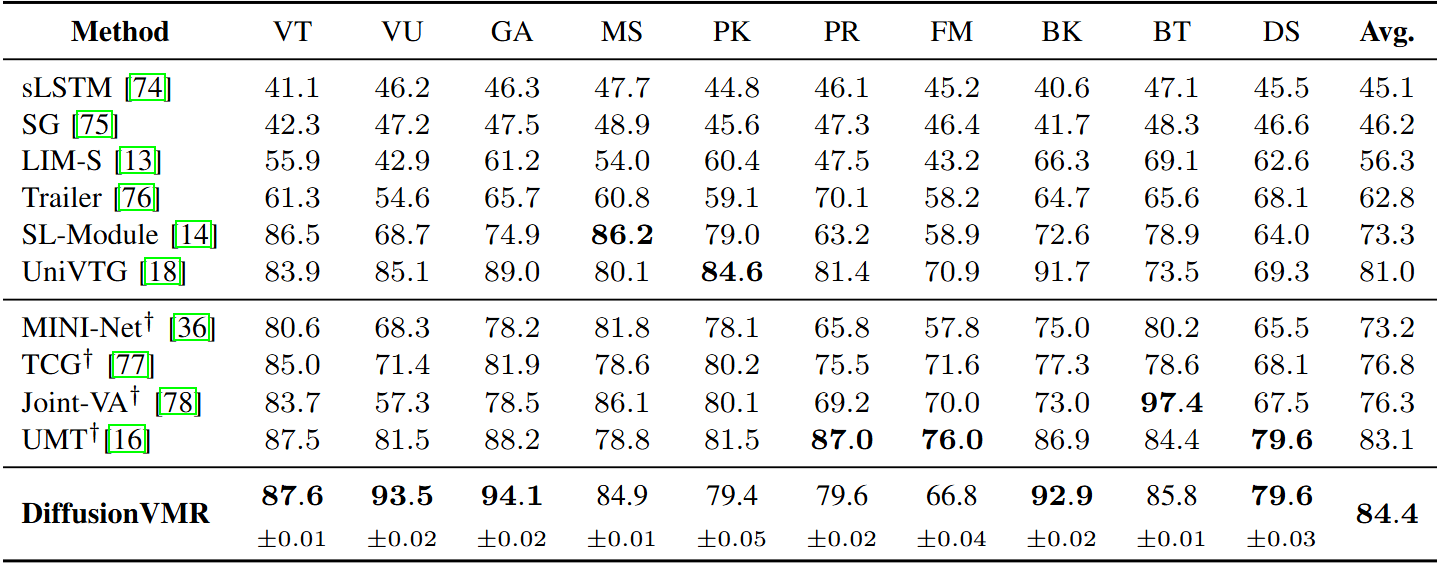
高光检测
baseline对比
采样步数和候选数量(20,50,70)
损失函数消融实验
训练策略,固定proposal还是逐步增加
