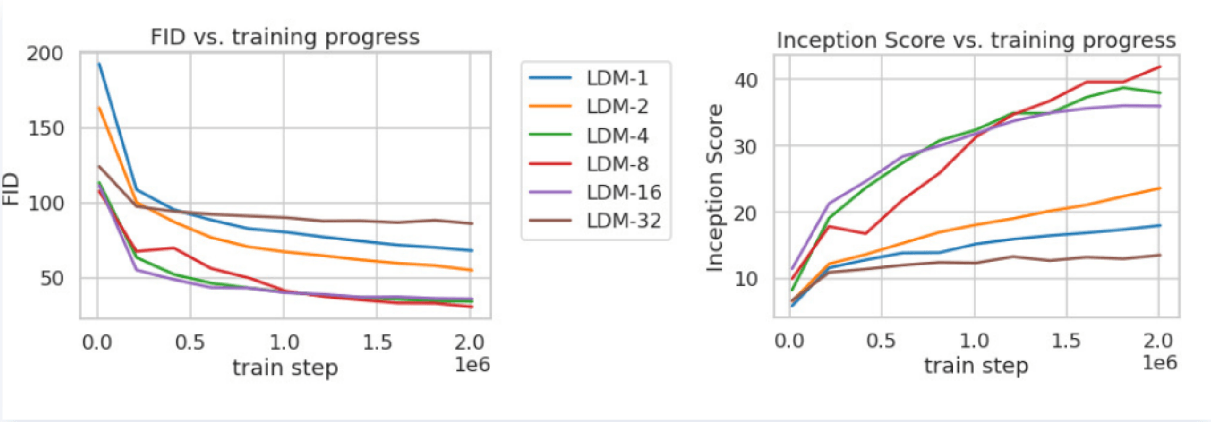
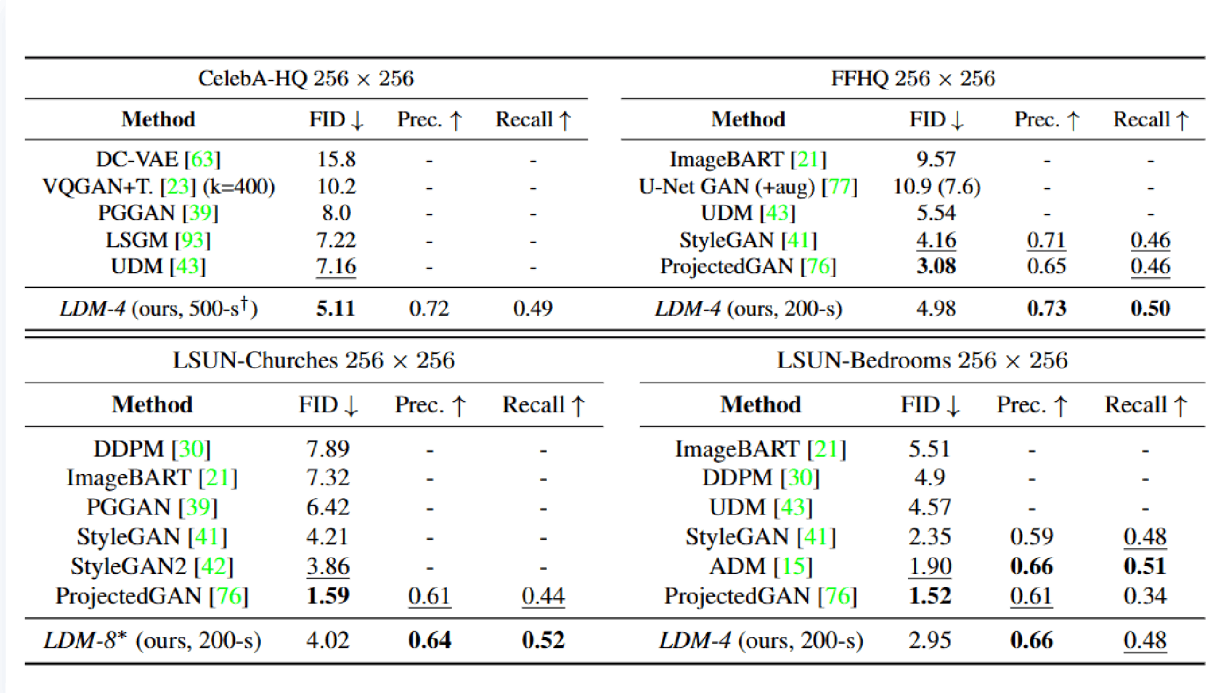
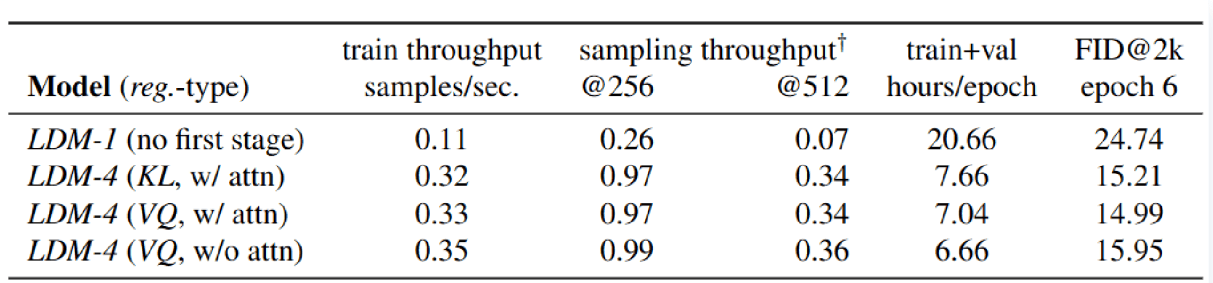
论文发布时间:2022.4
论文发布会议:CVPR
Abstract
- 由于像素空间太大,DMs的训练通常需要上百个GPU天,并且推理十分高昂。
- 为了在有限的计算资源上进行DM训练,同时保持质量和灵活性,可以利用自编码器的潜在空间进行训练,可以大大降低成本。
- 将交叉注意力机制引入去噪模型架构,可以将扩散模型转为强大灵活的生成器,可用于一般条件限制输入。
Introduction
问题
如何降低扩散模型在图像合成方向的训练和推理计算量,如何实现一种有效压缩方法能保留更高层次的语义信息。
动机
- 目前的diffusion模型在图像合成方向取得了良好效果,但是由于其模式覆盖行为极其容易花费过多的成本,特别是在高分辨率图像中的高维空间中。因此需要提出一种方法,在不过多损害它的性能的情况下降低训练和采样复杂性。
- 目前的自编码器加GAN实现的感知压缩虽然去掉了图像中高频的不可感知的细节,但保留了大部分视觉内容,压缩率较低。现在需要提出一种方法进行语义压缩,有更大高压缩率的同时,保留图像中更高层次的语义信息而不是细节。
方案
两阶段训练
- 训练一个自动编码器,提供一个低维而有效的空间,这个空间在感知上与数据空间等价,但大大降低了计算复杂度。训练完的自编码器可以用到多个DM重复训练,有良好的可复用性。
- 在与数据空间感知等价的潜在空间中进行扩散模型的训练,避免了对空间的过度压缩,提升了对空间维度的扩展性。
Method
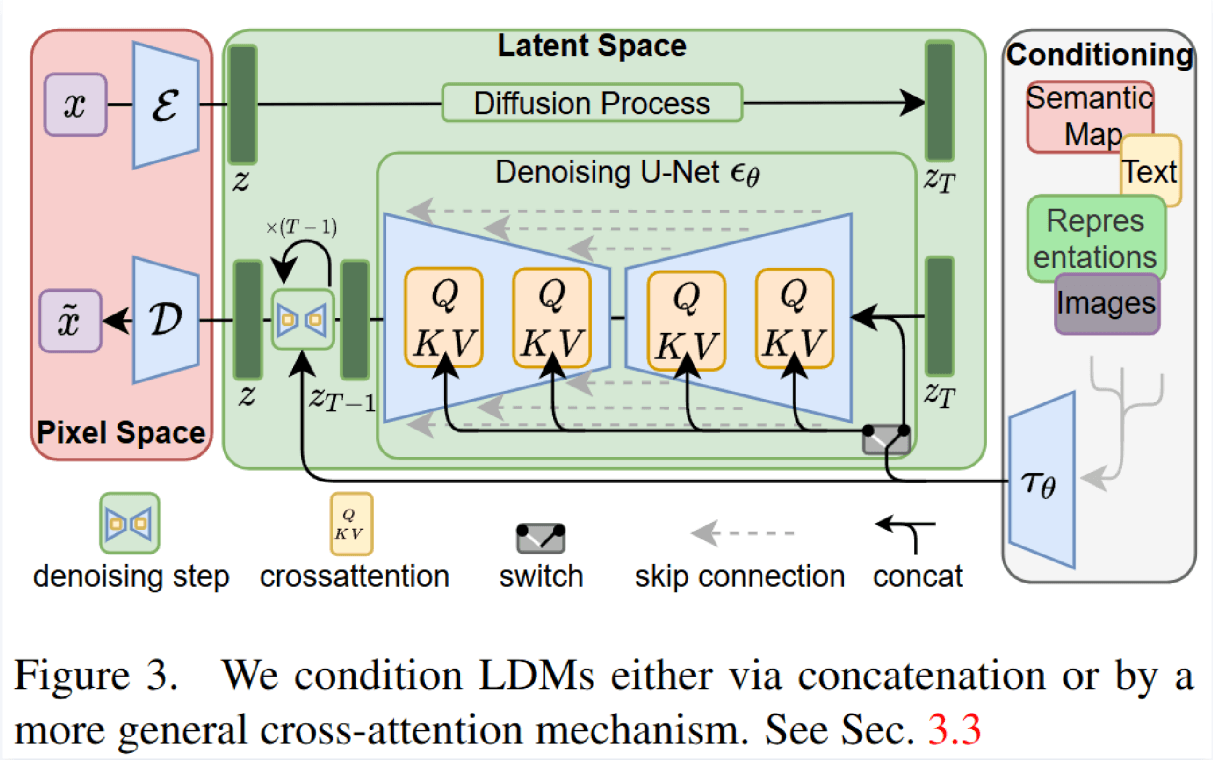
Perceptual Image Compression
LDM的感知压缩模型基于之前的工作,结合了感知损失(perceptual loss)和基于局部的对抗性目标(patch-based adversarial objective)进行训练。这样的组合确保了图像的重建局限于图像流形(image manifold),以保持局部的真实感,并避免使用像素空间损失(如
具体来说,给定一张RGB图像
为了避免潜在空间
- KL正则化(KL-reg):类似于变分自编码器(VAE),对潜在空间施加轻微的KL惩罚,使其逼近标准正态分布。
- VQ正则化(VQ-reg):在解码器中使用向量量化层,类似于VQGAN模型,但将量化层吸收到解码器中。
与之前的工作不同,LDM在潜在空间
Latent Diffusion Models
Diffusion Models
扩散模型是一类概率模型,其设计目的是通过逐渐去噪一个正态分布的变量,来学习数据分布
这些扩散模型可以解释为一系列去噪自编码器
其中,
Generative Modeling of Latent Representations
通过训练好的感知压缩模型(由编码器
1. 关注数据中重要的语义信息;
2. 在一个低维且计算更高效的空间中进行训练。
与之前依赖于自回归、注意力机制的Transformer模型在高度压缩的离散潜在空间中的工作不同,LDM可以充分利用模型提供的图像特定的归纳偏置(inductive bias)。这包括以下能力:
- 主要基于二维卷积层构建底层的UNet;
- 将目标聚焦于感知上最相关的信息,使用重新加权的下界。
重新加权的下界目标函数现在表示为:
其中,
在训练过程中,潜在表示
Conditioning Mechanisms
类似于其他类型的生成模型,扩散模型也能够建模条件分布
在图像生成的背景下,将扩散模型与其他类型的条件输入(如类别标签以外的输入)结合起来,目前仍是一个被较少探索的领域。为此,LDM通过增强其底层的UNet结构,并引入交叉注意力机制(cross-attention mechanism),使其成为更灵活的条件图像生成器。
交叉注意力机制
为了处理不同模态的输入
其中:
条件LDM的训练目标
基于图像和条件对
其中
Experiments